


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Idomura, Yasuhiro; Ina, Takuya*; Ali, Y.*; Imamura, Toshiyuki*
Dai-34-Kai Suchi Ryutai Rikigaku Shimpojiumu Koen Rombunshu (Internet), 6 Pages, 2020/12
A new communication avoiding (CA) Krylov solver with a FP16 (half precision) preconditioner is developed for a semi-implicit finite difference solver in the Gyrokinetic Toroidal 5D full-f Eulerian code GT5D. In the solver, the bottleneck of global collective communication is resolved using a CA-Krylov subspace method, and halo data communication is reduced by the FP16 preconditioner, which improves the convergence property. The FP16 preconditioner is designed based on the physics properties of the operator and is implemented using the new support for FP16 SIMD operations on A64FX. The solver is ported also on GPUs, and the performance of ITER size simulations with 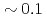 trillion grids is measured on Fugaku (A64FX) and Summit (V100). The new solver accelerates GT5D by
trillion grids is measured on Fugaku (A64FX) and Summit (V100). The new solver accelerates GT5D by 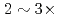 from the conventional non-CA solver, and excellent strong scaling is obtained up to 5,760 CPUs/GPUs both on Fugaku and Summit.
from the conventional non-CA solver, and excellent strong scaling is obtained up to 5,760 CPUs/GPUs both on Fugaku and Summit.
Idomura, Yasuhiro; Ina, Takuya*; Ali, Y.*; Imamura, Toshiyuki*
Proceedings of International Conference for High Performance Computing, Networking, Storage, and Analysis (SC 2020) (Internet), p.1318 - 1330, 2020/11
Times Cited Count:2 Percentile:46.34(Computer Science, Information Systems)The multi-scale full-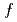 simulation of the next generation experimental fusion reactor ITER based on a five dimensional (5D) gyrokinetic model is one of the most computationally demanding problems in fusion science. In this work, a Gyrokinetic Toroidal 5D Eulerian code (GT5D) is accelerated by a new mixed-precision communication-avoiding (CA) Krylov method. The bottleneck of global collective communication on accelerated computing platforms is resolved using a CA Krylov method. In addition, a new FP16 preconditioner, which is designed using the new support for FP16 SIMD operations on A64FX, reduces both the number of iterations (halo data communication) and the computational cost. The performance of the proposed method for ITER size simulations with 0.1 trillion grids on 1,440 CPUs/GPUs on Fugaku and Summit shows 2.8x and 1.9x speedups respectively from the conventional non-CA Krylov method, and excellent strong scaling is obtained up to 5,760 CPUs/GPUs.
simulation of the next generation experimental fusion reactor ITER based on a five dimensional (5D) gyrokinetic model is one of the most computationally demanding problems in fusion science. In this work, a Gyrokinetic Toroidal 5D Eulerian code (GT5D) is accelerated by a new mixed-precision communication-avoiding (CA) Krylov method. The bottleneck of global collective communication on accelerated computing platforms is resolved using a CA Krylov method. In addition, a new FP16 preconditioner, which is designed using the new support for FP16 SIMD operations on A64FX, reduces both the number of iterations (halo data communication) and the computational cost. The performance of the proposed method for ITER size simulations with 0.1 trillion grids on 1,440 CPUs/GPUs on Fugaku and Summit shows 2.8x and 1.9x speedups respectively from the conventional non-CA Krylov method, and excellent strong scaling is obtained up to 5,760 CPUs/GPUs.
Idomura, Yasuhiro; Ina, Takuya*; Ali, Y.*; Imamura, Toshiyuki*
Proceedings of Joint International Conference on Supercomputing in Nuclear Applications + Monte Carlo 2020 (SNA + MC 2020), p.225 - 230, 2020/10
A new communication avoiding (CA) Krylov solver with a FP16 (half precision) preconditioner is developed for a semi-implicit finite difference solver in the Gyrokinetic Toroidal 5D full-f Eulerian code GT5D. In the solver, the bottleneck of global collective communication is resolved using a CA-Krylov subspace method, while the number of halo data communication is reduced by improving the convergence property using the FP16 preconditioner. The FP16 preconditioner is designed based on the physics properties of the operator and is implemented using the new support for FP16 SIMD operations on A64FX. The solver is ported on Fugaku (A64FX) and Summit (V100), which respectively show 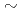 63x and 29x speedups in socket performance compared to the conventional non-CA Krylov solver on JAEA-ICEX (Haswell).
63x and 29x speedups in socket performance compared to the conventional non-CA Krylov solver on JAEA-ICEX (Haswell).
Onodera, Naoyuki; Idomura, Yasuhiro; Ali, Y.*; Yamashita, Susumu; Shimokawabe, Takashi*; Aoki, Takayuki*
Proceedings of Joint International Conference on Supercomputing in Nuclear Applications + Monte Carlo 2020 (SNA + MC 2020), p.210 - 215, 2020/10
This paper presents a GPU-based Poisson solver on a block-based adaptive mesh refinement (block-AMR) framework. The block-AMR method is essential for GPU computation and efficient description of the nuclear reactor. In this paper, we successfully implement a conjugate gradient method with a state-of-the-art multi-grid preconditioner (MG-CG) on the block-AMR framework. GPU kernel performance was measured on the GPU-based supercomputer TSUBAME3.0. The bandwidth of a vector-vector sum, a matrix-vector product, and a dot product in the CG kernel gave good performance at about 60% of the peak performance. In the MG kernel, the smoothers in a three-stage V-cycle MG method are implemented using a mixed precision RB-SOR method, which also gave good performance. For a large-scale Poisson problem with 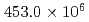 cells, the developed MG-CG method reduced the number of iterations to less than 30% and achieved
cells, the developed MG-CG method reduced the number of iterations to less than 30% and achieved 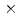 2.5 speedup compared with the original preconditioned CG method.
2.5 speedup compared with the original preconditioned CG method.
Onodera, Naoyuki; Idomura, Yasuhiro; Ali, Y.*; Shimokawabe, Takashi*; Aoki, Takayuki*
Keisan Kogaku Koenkai Rombunshu (CD-ROM), 25, 4 Pages, 2020/06
We have developed the stencil-based CFD code JUPITER for simulating three-dimensional multiphase flows. A GPU-accelerated Poisson solver based on the preconditioned conjugate gradient (P-CG) method with a multigrid preconditioner was developed for the JUPITER with block-structured AMR mesh. All Poisson kernels were implemented using CUDA, and the GPU kernel function is well tuned to achieve high performance on GPU supercomputers. The developed multigrid solver shows good convergence of about 1/7 compared with the original P-CG method, and 3 speed up is achieved with strong scaling test from 8 to 216 GPUs on TSUBAME 3.0.
Ali, Y.*; Onodera, Naoyuki; Idomura, Yasuhiro; Ina, Takuya*; Imamura, Toshiyuki*
Proceedings of 10th Workshop on Latest Advances in Scalable Algorithms for Large-Scale Systems (ScalA 2019), p.1 - 8, 2019/11
Times Cited Count:11 Percentile:93.69(Computer Science, Theory & Methods)Iterative methods for solving large linear systems are common parts of computational fluid dynamics (CFD) codes. The Preconditioned Conjugate Gradient (P-CG) method is one of the most widely used iterative methods. However, in the P-CG method, global collective communication is a crucial bottleneck especially on accelerated computing platforms. To resolve this issue, communication avoiding (CA) variants of the P-CG method are becoming increasingly important. In this paper, the P-CG and Preconditioned Chebyshev Basis CA CG (P-CBCG) solvers in the multiphase CFD code JUPITER are ported to the latest V100 GPUs. All GPU kernels are highly optimized to achieve about 90% of the roofline performance, the block Jacobi preconditioner is re-designed to extract high computing power of GPUs, and the remaining bottleneck of halo data communication is avoided by overlapping communication and computation. The overall performance of the P-CG and P-CBCG solvers is determined by the competition between the CA properties of the global collective communication and the halo data communication, indicating an importance of the inter-node interconnect bandwidth per GPU. The developed GPU solvers are accelerated up to 2x compared with the former CPU solvers on KNLs, and excellent strong scaling is achieved up to 7,680 GPUs on the Summit.
Onodera, Naoyuki; Idomura, Yasuhiro; Ali, Y.*; Shimokawabe, Takashi*
Proceedings of 9th Workshop on Latest Advances in Scalable Algorithms for Large-Scale Systems (ScalA 2018) (Internet), p.9 - 16, 2018/11
Times Cited Count:10 Percentile:92.63(Computer Science, Theory & Methods)We develop a communication reduced multi-time- step (CRMT) algorithm for a Lattice Boltzmann method (LBM) based on a block-structured adaptive mesh refinement (AMR). This algorithm is based on the temporal blocking method, and can improve computational efficiency by replacing a communication bottleneck with additional computation. The proposed method is implemented on an extreme scale airflow simulation code CityLBM, and its impact on the scalability is tested on GPU based supercomputers, TSUBAME and Reedbush. Thanks to the CRMT algorithm, the communication cost is reduced by 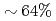 , and weak and strong scalings are improved up to
, and weak and strong scalings are improved up to 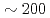 GPUs. The obtained performance indicates that real time airflow simulations for about 2km square area with the wind speed of
GPUs. The obtained performance indicates that real time airflow simulations for about 2km square area with the wind speed of 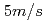 is feasible using 1m resolution.
is feasible using 1m resolution.
Widmann, M.*; Lee, S.-Y.*; Rendler, T.*; Son, N. T.*; Fedder, H.*; Paik, S.*; Yang, L.-P.*; Zhao, N.*; Yang, S.*; Booker, I.*; et al.
Nature Materials, 14(2), p.164 - 168, 2015/02
Times Cited Count:508 Percentile:99.58(Chemistry, Physical)Waldherr, G.*; Wang, Y.*; Zaiser, S.*; Jamali, M.*; Schulte-Herbr ggen, T.*; Abe, Hiroshi; Oshima, Takeshi; Isoya, Junichi*; Du, J. F.*; Neumann, P.*; et al.
ggen, T.*; Abe, Hiroshi; Oshima, Takeshi; Isoya, Junichi*; Du, J. F.*; Neumann, P.*; et al.
Nature, 506(7487), p.204 - 207, 2014/02
Times Cited Count:471 Percentile:99.58(Multidisciplinary Sciences)no abstracts in English
Bonfigli, F.*; Faenov, A. Y.; Flora, F.*; Francucci, M.*; Gaudio, P.*; Lai, A.*; Martellucci, S.*; Montereali, R. M.*; Pikuz, T.*; Reale, L.*; et al.
Microscopy Research and Technique, 71(1), p.35 - 41, 2008/01
Times Cited Count:30 Percentile:76.53(Anatomy & Morphology)Batistoni, P.*; Angelone, M.*; Bettinali, L.*; Carconi, P.*; Fischer, U.*; Kodeli, I.*; Leichtle, D.*; Ochiai, Kentaro; Perel, R.*; Pillon, M.*; et al.
Fusion Engineering and Design, 82(15-24), p.2095 - 2104, 2007/10
Times Cited Count:27 Percentile:83.96(Nuclear Science & Technology)A neutronics experiment has been performed in the frame of European Fusion Technology Program on a mock-up of the EU Test Blanket Module (TBM), Helium Cooled Pebble Bed (HCPB) concept, with the objective to validate the capability of nuclear data to predict nuclear responses, such as the tritium production rate (TPR), with qualified uncertainties. In the experiment, the TPR has been measured using Li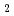 CO
CO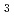 pellets at various depths at two symmetrical positions at each depth, one in the upper and one in the lower breeder cassette. Three independent measurements were performed by ENEA, TUD/VKTA and JAEA. The neutron flux in the beryllium layer was measured as well using activation foils.
pellets at various depths at two symmetrical positions at each depth, one in the upper and one in the lower breeder cassette. Three independent measurements were performed by ENEA, TUD/VKTA and JAEA. The neutron flux in the beryllium layer was measured as well using activation foils.
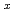 produced by low-energy ion implantation
produced by low-energy ion implantationAli, M.; Baba, Yuji; Sekiguchi, Tetsuhiro; Li, Y.; Yamamoto, Hiroyuki
Photon Factory Activity Report 1998, P. 36, 1999/11
no abstracts in English
S) on Si(100) following excitation of adsorbate or substrate core levelSekiguchi, Tetsuhiro; Baba, Yuji; Li, Y.; Ali, M.
Photon Factory Activity Report 1998, Part B, P. 67, 1999/11
no abstracts in English
Idomura, Yasuhiro; Ali, Y.*; Ina, Takuya*; Imamura, Toshiyuki*
no journal, ,
Implicit finite difference solvers based on Krylov subspace methods occupy dominant computing costs in the Gyrokinetic Toroidal 5D full-f Eulerian code GT5D. Under the post-K project, advanced communication avoiding (CA) Krylov subspace methods have been developed for exascale computing platforms, which have limited inter-node communication performance compared with accelerated computation. In this work, we develop a new mixed precision CA-GMRES solver using a FP16 preconditioner, which dramatically reduces the number of iterations, and thus, halo data communications. We port the new solver on FUGAKU and Summit, and compare its performance against conventional solvers on existing muti/many-core processors.
Ali, Y.*; Onodera, Naoyuki; Idomura, Yasuhiro; Ina, Takuya*; Imamura, Toshiyuki*
no journal, ,
Krylov solvers can account for up to 90% of the total computing cost in extreme scale nuclear CFD simulations. In order to accelerate such CFD codes, we ported the conventional Preconditioned Conjugate Gradient (PCG) and the two latest communication avoiding algorithms, the Preconditioned Chebyshev Basis communication-avoiding Conjugate Gradient (P-CBCG) and the Communication-Avoiding Generalized Minimal RESidual (CA-GMRES) methods, on to GPUs. In this talk, we discuss a trade-off between the performance portability and the performance improvement for implementations using OpenACC and CUDA, and show performance tests on the latest GPU supercomputers.
Ali, Y.*; Ina, Takuya*; Onodera, Naoyuki; Idomura, Yasuhiro
no journal, ,
Krylov subspace solvers for the pressure Poisson equation occupy 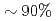 of the total computing cost in extreme scale multi-phase CFD simulation. To accelerate the Poisson solver, we port a Chebyshev Basis communication-avoiding Conjugate Gradient (CBCG) solver with block Jacobi (BJ) preconditioning on P100 GPUs. The CBCG solver consists of BJ preconditioning, Sparse Matrix Vector product (SpMV), and Tall-Skinny matrix operations. We re-design the BJ-preconditioner for thread-block parallelization and efficient coalescing data load, and apply batched gemm to the Tall-Skinny matrix operations. By these optimization, all main kernels achieved of the theoretical performance based on roofline estimation, and an order of magnitude speedup of the single node performance was obtained against CPU nodes.
of the total computing cost in extreme scale multi-phase CFD simulation. To accelerate the Poisson solver, we port a Chebyshev Basis communication-avoiding Conjugate Gradient (CBCG) solver with block Jacobi (BJ) preconditioning on P100 GPUs. The CBCG solver consists of BJ preconditioning, Sparse Matrix Vector product (SpMV), and Tall-Skinny matrix operations. We re-design the BJ-preconditioner for thread-block parallelization and efficient coalescing data load, and apply batched gemm to the Tall-Skinny matrix operations. By these optimization, all main kernels achieved of the theoretical performance based on roofline estimation, and an order of magnitude speedup of the single node performance was obtained against CPU nodes.
Idomura, Yasuhiro; Ali, Y.*; Onodera, Naoyuki; Hasegawa, Yuta; Ina, Takuya*
no journal, ,
Krylov solvers can account for up to of the total computing cost in extreme scale nuclear CFD simulations. In order to accelerate such CFD codes, we ported the Preconditioned Conjugate Gradient (PCG), Preconditioned Chebyshev Basis communication-avoiding Conjugate Gradient (P-CBCG) and Communication-Avoiding Generalized Minimal RESidual (CA-GMRES) methods on to GPUs. In this talk, we will share our experiences in porting these solvers via OpenACC, CUDA, and CUDA aware MPI.
Onodera, Naoyuki; Idomura, Yasuhiro; Ali, Y.*; Shimokawabe, Takashi*
no journal, ,
A thermal flow analysis is one of important topics for decommissioning the TEPCO's Fukushima Daiichi Nuclear Power Station. Japan Atomic Energy Agency (JAEA) has been evaluating the air cooling performance of the fuel debris by using the JUPITER code, which is based on an incompressible fluid model on uniform Cartesian grids. However, the JUPITER code requires a large computational cost to capture complicated debris' structures at the actual scale. To accelerate such air cooling analyses, we use the CityLBM code, which is developed using a locally mesh refined lattice Boltzmann method (LBM) and is highly optimized for GPUs. The CityLBM code is validated against free convective heat transfer experiments at JAEA.
Onodera, Naoyuki; Idomura, Yasuhiro; Ali, Y.*; Yamashita, Susumu; Ina, Takuya*; Imamura, Toshiyuki*
no journal, ,
Transient heat flow analysis of nuclear reactors is very important from the view point of efficient design and safety. We have developed the stencil-based CFD code JUPITER for simulating three-dimensional multiphase flows. We extended the JUPITER with GPU-accelerated Poisson solvers based on the P-CG and P-CBCG methods. All main kernels were implemented using CUDA, and the GPU kernel function is well tuned to achieve high performance on the latest Volta-core GPUs. The developed solvers showed good strong scaling up to 2,048 GPUs/CPUs on the Summit (NVIDIA TESLA V100), the ABCI (NVIDIA TESLA V100), the Oakforest-PACS (Intel Knights Landing). Finally, the performance gain from the Oakforest-PACS ranges from 1.2 1.6x on the Summit and 1.4 1.7x on the ABCI, respectively.
Onodera, Naoyuki; Idomura, Yasuhiro; Ali, Y.*
no journal, ,
A real-time simulation of the environmental dynamics of radioactive substances is very important from the viewpoint of nuclear security. Since a lot of tall buildings and complex structures make the air flow turbulent in urban cities, large-scale CFD simulations are needed. To this end, a CFD code based on a Lattice Boltzmann Method (LBM) with a block-based Adaptive Mesh Refinement (AMR) method is developed. As the conventional LBM based on a single relaxation time collision operator often becomes numerically unstable at high Reynolds number, we apply a state-of-the-art cumulant collision operator. The code is developed on a GPU cluster at JAEA. By using new functions in CUDA8.0, the GPU kernel functions are tuned to achieve high performance on the latest Pascal GPU architecture. By introducing a temporal blocking technique, we achieve a high performance of 488 MLUPS per a GPU, and the number of the MPI communications is significantly reduced.
