


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Watanabe, Seiya*; Kawahara, Jun*; Aoki, Takayuki*; Sugihara, Kenta; Takase, Shinsuke*; Moriguchi, Shuji*; Hashimoto, Hirotada*
Engineering Applications of Computational Fluid Mechanics, 17(1), p.2211143_1 - 2211143_23, 2023/00
Times Cited Count:1 Percentile:61.52(Engineering, Multidisciplinary)In tsunami inundations or slope disasters of heavy rain, a lot of floating debris or driftwood logs are included in the flows. The damage to structures from solid body impacts is more severe than the damage from the water pressure. In order to study free-surface flows that include floating debris, developing a high-accurate simulation code of free-surface flows with high performance for large-scale computations is desired. We propose the single-phase free-surface flow model based on the cumulant lattice Boltzmann method coupled with a particle-based rigid body simulation. The discrete element method calculates the contact interaction between solids. An octree-based AMR (Adaptive Mesh Refinement) method is introduced to improve computational accuracy and time-to-solution. High-resolution grids are assigned near the free surfaces and solid boundaries. We conducted two kinds of tsunami flow experiments in the 15 and 70 m water tanks at Hachinohe Institute of Technology and Kobe University to validate the accuracy of the proposed model. The simulation results have shown good agreement with the experiments for the drifting speed, the number of trapped wood pieces, and the stacked angles.
Onodera, Naoyuki; Idomura, Yasuhiro; Hasegawa, Yuta; Shimokawabe, Takashi*; Aoki, Takayuki*
Keisan Kogaku Koenkai Rombunshu (CD-ROM), 27, 4 Pages, 2022/06
We have developed a wind simulation code named CityLBM to realize wind digital twins. Mesoscale wind conditions are given as boundary conditions in CityLBM by using a nudging data assimilation method. It is found that conventional approaches with constant nudging coefficients fail to reproduce turbulent intensity in long time simulations, where atmospheric stability conditions change significantly. We propose a dynamic parameter optimization method for the nudging coefficient based on a particle filter. CityLBM was validated against plume dispersion experiments in the complex urban environment of Oklahoma City. The nudging coefficient was updated to reduce the error of the turbulent intensity between the simulation and the observation, and the atmospheric boundary layer was reproduced throughout the day.
Hasegawa, Yuta; Aoki, Takayuki*; Kobayashi, Hiromichi*; Idomura, Yasuhiro; Onodera, Naoyuki
Parallel Computing, 108, p.102851_1 - 102851_12, 2021/12
Times Cited Count:2 Percentile:32.94(Computer Science, Theory & Methods)The aerodynamics simulation code based on the lattice Boltzmann method (LBM) using forest-of-octrees-based block-structured local mesh refinement (LMR) was implemented, and its performance was evaluated on GPU-based supercomputers. We found that the conventional Space-Filling-Curve-based (SFC) domain partitioning algorithm results in costly halo communication in our aerodynamics simulations. Our new tree cutting approach improved the locality and the topology of the partitioned sub-domains and reduced the communication cost to one-third or one-fourth of the original SFC approach. In the strong scaling test, the code achieved maximum 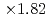 speedup at the performance of 2207 MLUPS (mega- lattice update per second) on 128 GPUs. In the weak scaling test, the code achieved 9620 MLUPS at 128 GPUs with 4.473 billion grid points, while the parallel efficiency was 93.4% from 8 to 128 GPUs.
speedup at the performance of 2207 MLUPS (mega- lattice update per second) on 128 GPUs. In the weak scaling test, the code achieved 9620 MLUPS at 128 GPUs with 4.473 billion grid points, while the parallel efficiency was 93.4% from 8 to 128 GPUs.
Onodera, Naoyuki; Idomura, Yasuhiro; Hasegawa, Yuta; Nakayama, Hiromasa; Shimokawabe, Takashi*; Aoki, Takayuki*
Boundary-Layer Meteorology, 179(2), p.187 - 208, 2021/05
Times Cited Count:12 Percentile:75.33(Meteorology & Atmospheric Sciences)A plume dispersion simulation code named CityLBM enables a real time simulation for several km by applying adaptive mesh refinement (AMR) method on GPU supercomputers. We assess plume dispersion problems in the complex urban environment of Oklahoma City (JU2003). Realistic mesoscale wind boundary conditions of JU2003 produced by a Weather Research and Forecasting Model (WRF), building structures, and a plant canopy model are introduced to CityLBM. Ensemble calculations are performed to reduce turbulence uncertainties. The statistics of the plume dispersion field, mean and max concentrations show that ensemble calculations improve the accuracy of the estimation, and the ensemble-averaged concentration values in the simulations over 4 km areas with 2-m resolution satisfied factor 2 agreements for 70% of 24 target measurement points and periods in JU2003.
Hasegawa, Yuta; Aoki, Takayuki*; Kobayashi, Hiromichi*; Idomura, Yasuhiro; Onodera, Naoyuki
Keisan Kogaku Koenkai Rombunshu (CD-ROM), 26, 6 Pages, 2021/05
We introduce an improved domain partitioning method called "tree cutting approach" for the aerodynamics simulation code based on the lattice Boltzmann method (LBM) with the forest-of-octrees-based local mesh refinement (LMR). The conventional domain partitioning algorithm based on the space-filling curve (SFC), which is widely used in LMR, caused a costly halo data communication which became a bottleneck of our aerodynamics simulation on the GPU-based supercomputers. Our tree cutting approach adopts a hybrid domain partitioning with the coarse structured block decomposition and the SFC partitioning in each block. This hybrid approach improved the locality and the topology of the partitioned sub-domains and reduced the amount of the halo communication to one-third of the original SFC approach. The code achieved 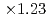 speedup on 8 GPUs, and achieved
speedup on 8 GPUs, and achieved 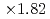 speedup at the performance of 2207 MLUPS (mega-lattice update per second) on 128 GPUs with strong scaling test.
speedup at the performance of 2207 MLUPS (mega-lattice update per second) on 128 GPUs with strong scaling test.
Onodera, Naoyuki; Idomura, Yasuhiro; Hasegawa, Yuta; Shimokawabe, Takashi*; Aoki, Takayuki*
Keisan Kogaku Koenkai Rombunshu (CD-ROM), 26, 3 Pages, 2021/05
We develop a mixed-precision preconditioner for the pressure Poisson equation in a two-phase flow CFD code JUPITER-AMR. The multi-grid (MG) preconditioner is constructed based on the geometric MG method with a three- stage V-cycle, and a cache-reuse SOR (CR-SOR) method at each stage. The numerical experiments are conducted for two-phase flows in a fuel bundle of a nuclear reactor. The MG-CG solver in single-precision shows the same convergence histories as double-precision, which is about 75% of the computational time in double-precision. In the strong scaling test, the MG-CG solver in single-precision is accelerated by 1.88 times between 32 and 96 GPUs.
Onodera, Naoyuki; Idomura, Yasuhiro; Hasegawa, Yuta; Yamashita, Susumu; Shimokawabe, Takashi*; Aoki, Takayuki*
Proceedings of International Conference on High Performance Computing in Asia-Pacific Region (HPC Asia 2021) (Internet), p.120 - 128, 2021/01
Times Cited Count:0 Percentile:0.01(Computer Science, Hardware & Architecture)We develop a multigrid preconditioned conjugate gradient (MG-CG) solver for the pressure Poisson equation in a two-phase flow CFD code JUPITER. The MG preconditioner is constructed based on the geometric MG method with a three-stage V-cycle, and a RB-SOR smoother and its variant with cache-reuse optimization (CR-SOR) are applied at each stage. The numerical experiments are conducted for two-phase flows in a fuel bundle of a nuclear reactor. The MG-CG solvers with the RB-SOR and CR-SOR smoothers reduce the number of iterations to less than 15% and 9% of the original preconditioned CG method, leading to 3.1- and 5.9-times speedups, respectively. The obtained performance indicates that the MG-CG solver designed for the block-structured grid is highly efficient and enables large-scale simulations of two-phase flows on GPU based supercomputers.
Onodera, Naoyuki; Idomura, Yasuhiro; Asahi, Yuichi; Hasegawa, Yuta; Shimokawabe, Takashi*; Aoki, Takayuki*
Dai-34-Kai Suchi Ryutai Rikigaku Shimpojiumu Koen Rombunshu (Internet), 2 Pages, 2020/12
We develop a multigrid preconditioned conjugate gradient (MG-CG) solver for the pressure Poisson equation in a two-phase flow CFD code JUPITER. The code is written in C++ and CUDA to keep the portability on multi-platforms. The main kernels of the CG solver achieve reasonable performance as 0.4 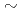 0.75 of the roofline performances, and the performances of the MG-preconditioner are also reasonable on NVIDIA GPU and Intel CPU. However, the performance degradation of the SpMV kernel on ARM is significant. It is confirmed that the optimization does not work if any functions are included in the loop.
0.75 of the roofline performances, and the performances of the MG-preconditioner are also reasonable on NVIDIA GPU and Intel CPU. However, the performance degradation of the SpMV kernel on ARM is significant. It is confirmed that the optimization does not work if any functions are included in the loop.
Onodera, Naoyuki; Idomura, Yasuhiro; Ali, Y.*; Yamashita, Susumu; Shimokawabe, Takashi*; Aoki, Takayuki*
Proceedings of Joint International Conference on Supercomputing in Nuclear Applications + Monte Carlo 2020 (SNA + MC 2020), p.210 - 215, 2020/10
This paper presents a GPU-based Poisson solver on a block-based adaptive mesh refinement (block-AMR) framework. The block-AMR method is essential for GPU computation and efficient description of the nuclear reactor. In this paper, we successfully implement a conjugate gradient method with a state-of-the-art multi-grid preconditioner (MG-CG) on the block-AMR framework. GPU kernel performance was measured on the GPU-based supercomputer TSUBAME3.0. The bandwidth of a vector-vector sum, a matrix-vector product, and a dot product in the CG kernel gave good performance at about 60% of the peak performance. In the MG kernel, the smoothers in a three-stage V-cycle MG method are implemented using a mixed precision RB-SOR method, which also gave good performance. For a large-scale Poisson problem with 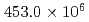 cells, the developed MG-CG method reduced the number of iterations to less than 30% and achieved
cells, the developed MG-CG method reduced the number of iterations to less than 30% and achieved 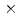 2.5 speedup compared with the original preconditioned CG method.
2.5 speedup compared with the original preconditioned CG method.
Onodera, Naoyuki; Idomura, Yasuhiro; Ali, Y.*; Shimokawabe, Takashi*; Aoki, Takayuki*
Keisan Kogaku Koenkai Rombunshu (CD-ROM), 25, 4 Pages, 2020/06
We have developed the stencil-based CFD code JUPITER for simulating three-dimensional multiphase flows. A GPU-accelerated Poisson solver based on the preconditioned conjugate gradient (P-CG) method with a multigrid preconditioner was developed for the JUPITER with block-structured AMR mesh. All Poisson kernels were implemented using CUDA, and the GPU kernel function is well tuned to achieve high performance on GPU supercomputers. The developed multigrid solver shows good convergence of about 1/7 compared with the original P-CG method, and 3 speed up is achieved with strong scaling test from 8 to 216 GPUs on TSUBAME 3.0.
Aoki, Takayuki*; Hasegawa, Yuta
Jidosha Gijutsu, 74(4), p.18 - 23, 2020/04
Aerodynamics studies for bicycle racings have been carried out by using a CFD simulation based on LES model. For running of alone cyclist and 2-4 cyclists groups, the computational drags are in good agreement with the wind-tunnel experiments. Different shapes of group running and competing two teams are studied. A large-scale computation for a group of 72 cyclists has been performed by using 2.23 billion meshes on a GPU supercomputer.
Inagaki, Atsushi*; Wangsaputra, Y.*; Kanda, Manabu*; Y cel, M.*; Onodera, Naoyuki; Aoki, Takayuki*
cel, M.*; Onodera, Naoyuki; Aoki, Takayuki*
SOLA (Scientific Online Letters on the Atmosphere) (Internet), 16, p.120 - 124, 2020/00
Times Cited Count:1 Percentile:4.56(Meteorology & Atmospheric Sciences)The similarity of the turbulence intensity profile with the inner-layer and the outer-layer scalings were examined for an urban boundary layer using numerical simulations. The simulations consider a developing neutral boundary layer over realistic building geometry. The computational domain covers an 19.2 km by 4.8 km and extends up to a height of 1 km with 2-m grids. Several turbulence intensity profiles are defined locally in the computational domain. The inner- and outer-layer scalings work well reducing the scatter of the turbulence intensity within the inner- and outer-layers, respectively, regardless of the surface geometry. Although the main scatters among the scaled profiles are attributed to the mismatch of the parts of the layer and the scaling parameters, their behaviors can also be explained by introducing a non-dimensional parameter which consists of the ratio of length or velocity.
Kawamura, Seiko; Hattori, Takanori; Harjo, S.; Ikeda, Kazutaka*; Miyata, Noboru*; Miyazaki, Tsukasa*; Aoki, Hiroyuki; Watanabe, Masao; Sakaguchi, Yoshifumi*; Oku, Takayuki
Neutron News, 30(1), p.11 - 13, 2019/05
In Japanese neutron scattering facilities, some SE equipment that are frequently used at an instrument, such as the closed-cycle refrigerator (CCR), have been prepared for the instrument as standard SE. They are operated for user experiments by the instrument group. The advantage of this practice is that they can optimize the design of the SE for the instrument and can directly respond to users' requests. On the other hand, the SE team in the Materials and Life Science Experimental Facility (MLF) in J-PARC has managed commonly used SE to allow neutron experiments with more advanced SE. In this report, recent SE in the MLF is introduced. Highlighted are the SE in BL11, BL19, BL21 and BL17 and other SE recently progressed by the SE team.
Strasser, P.*; Abe, Mitsushi*; Aoki, Masaharu*; Choi, S.*; Fukao, Yoshinori*; Higashi, Yoshitaka*; Higuchi, Takashi*; Iinuma, Hiromi*; Ikedo, Yutaka*; Ishida, Katsuhiko*; et al.
EPJ Web of Conferences, 198, p.00003_1 - 00003_8, 2019/01
Times Cited Count:13 Percentile:99.06(Quantum Science & Technology)Shimokawabe, Takashi*; Endo, Toshio*; Onodera, Naoyuki; Aoki, Takayuki*
Proceedings of 2017 IEEE International Conference on Cluster Computing (IEEE Cluster 2017) (Internet), p.525 - 529, 2017/09
Stencil-based applications such as CFD have succeeded in obtaining high performance on GPU supercomputers. The problem sizes of these applications are limited by the GPU device memory capacity, which is typically smaller than the host memory. On GPU supercomputers, a locality improvement technique using temporal blocking method with memory swapping between host and device enables large computation beyond the device memory capacity. Our high-productivity stencil framework automatically applies temporal blocking to boundary exchange required for stencil computation and supports automatic memory swapping provided by a MPI/CUDA wrapper library. The framework-based application for the airflow in an urban city maintains 80% performance even with the twice larger than the GPU memory capacity and have demonstrated good weak scalability on the TSUBAME 2.5 supercomputer.
Inagaki, Atsushi*; Kanda, Manabu*; Ahmad, N. H.*; Yagi, Ayako*; Onodera, Naoyuki; Aoki, Takayuki*
Boundary-Layer Meteorology, 164(2), p.161 - 181, 2017/08
Times Cited Count:30 Percentile:75.23(Meteorology & Atmospheric Sciences)The applicability of outer-layer scaling is examined by numerical simulation of a developing neutral boundary layer over a realistic building geometry of Tokyo. Large-eddy simulations are carried out over a large computational domain 19.2 km 4.8 km 1 km, with a fine grid spacing (2 m) using the lattice-Boltzmann method with massively parallel graphics processing units. Results from simulations show that outer-layer features are maintained for turbulence statistics in the upper part of the boundary layer, as well as the width of predominant streaky structures throughout the entire boundary layer. This is caused by the existence of very large streaky structures extending throughout the entire boundary layer, which follow outer-layer scaling with a self-preserving development. We assume the top-down mechanism in the physical interpretation of results.
Usui, Aya; Chiba, Atsuya; Yamada, Keisuke; Yokoyama, Akihito; Kitano, Toshihiko*; Takayama, Terumitsu*; Orimo, Takao*; Kanai, Shinji*; Aoki, Yuki*; Hashizume, Masashi*; et al.
Dai-28-Kai Tandemu Kasokuki Oyobi Sono Shuhen Gijutsu No Kenkyukai Hokokushu, p.117 - 119, 2015/12
no abstracts in English
Usui, Aya; Uno, Sadanori; Chiba, Atsuya; Yamada, Keisuke; Yokoyama, Akihito; Kitano, Toshihiko*; Takayama, Terumitsu*; Orimo, Takao*; Kanai, Shinji*; Aoki, Yuki*; et al.
Dai-27-Kai Tandemu Kasokuki Oyobi Sono Shuhen Gijutsu No Kenkyukai Hokokushu, p.118 - 121, 2015/03
no abstracts in English
Uno, Sadanori; Chiba, Atsuya; Yamada, Keisuke; Yokoyama, Akihito; Usui, Aya; Saito, Yuichi; Ishii, Yasuyuki; Sato, Takahiro; Okubo, Takeru; Nara, Takayuki; et al.
JAEA-Review 2013-059, JAEA Takasaki Annual Report 2012, P. 179, 2014/03
Three electrostatic accelerators at TIARA were operated on schedule in fiscal year 2012 except changing its schedule by cancellations of users. The yearly operation time of the 3 MV tandem accelerator, the 400 kV ion implanter and the 3MV single-ended accelerator were in the same levels as the ordinary one, whose operation time totaled to 2,073, 1,847 and 2,389 hours, respectively. The tandem accelerator had no trouble, whereas the ion implanter and the single-ended accelerator stopped by any troubles for one day and four days, respectively. The molecular ion beam of helium hydride was generated by the ion implanter, because the users required irradiation of several cluster ions in order to study the effect of irradiation. As a result, its intensity of beam was 50 nA at 200 kV. The ion beam of tungsten (W) at 15 MeV was accelerated by the tandem accelerator, whose intensity was 20 nA at charge state of 4+, because of the request from a researcher in the field of nuclear fusion.
Uno, Sadanori; Chiba, Atsuya; Yamada, Keisuke; Yokoyama, Akihito; Usui, Aya; Kitano, Toshihiko*; Takayama, Terumitsu*; Orimo, Takao*; Kanai, Shinji*; Aoki, Yuki*; et al.
Dai-26-Kai Tandemu Kasokuki Oyobi Sono Shuhen Gijutsu No Kenkyukai Hokokushu, p.79 - 81, 2013/07
Three electrostatic accelerators at TIARA were operated on schedule in fiscal year 2012 except changing its schedule by cancellations of users. The yearly operation time of the 3MV tandem accelerator, the 400 kV ion implanter and the 3 MV single-ended accelerator were in the same levels as the ordinary one, whose operation time totaled to 2,073, 1,847 and 2,389 hours, respectively. The tandem accelerator had no trouble, whereas the ion implanter and the single-ended accelerator stopped by any troubles for one day and four days, respectively. The ion implanter generated molecular ion beam of helium hydride by using the Freeman type ion source, because of the request from the user. As a result, its intensity of beam was 50 nA at 200 kV.
