


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
朝比 祐一; Padioleau, T.*; Latu, G.*; Bigot, J.*; Grandgirard, V.*; Obrejan, K.*
第36回数値流体力学シンポジウム講演論文集(インターネット), 8 Pages, 2022/12
本論文では、運動論的プラズマシミュレーションコードを例としてC++ parallel algorithm (stdpar)による性能可搬実装について論じる。言語標準の並列アルゴリズムstdparと抽象的高次元配列mdspanにより、可読性および生産性を損なわずに性能可搬な実装が可能であることを示す。抽象化により性能可搬性を実現するKokkosや、指示行によって性能可搬性を実現するOpenMPとの比較により、stdparの性能,可搬性,生産性などを論じる。Intel Icelake, NVIDIA V100およびA100 GPUにおいて、stdpar版のアプリケーションの性能はKokkos版に対し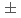 20%の範囲であった。将来的にAMDやIntel GPUにおいて利用可能になるという前提であれば、stdparはエクサスパコンにおいて有力な高生産かつ性能可搬な実装手法となり得る。
20%の範囲であった。将来的にAMDやIntel GPUにおいて利用可能になるという前提であれば、stdparはエクサスパコンにおいて有力な高生産かつ性能可搬な実装手法となり得る。
朝比 祐一; Padioleau, T.*; Latu, G.*; Bigot, J.*; Grandgirard, V.*; Obrejan, K.*
Proceedings of 2022 International Workshop on Performance, Portability, and Productivity in HPC (P3HPC) (Internet), p.68 - 80, 2022/11
被引用回数:6 パーセンタイル:75.01(Computer Science, Theory & Methods)本論文では、C++ parallel algorithmによる性能可搬な運動論的プラズマシミュレーションコードの実装について論じる。言語標準の並列アルゴリズムstdparと抽象的高次元配列mdspanにより、可読性および生産性を損なわずに性能可搬な実装が可能であることを示す。Intel Icelake、NVIDIA V100およびA100 GPUにおいて、アプリケーションの性能はKokkos版に対し 20%の範囲であった。将来的にAMDやIntel GPUにおいて利用可能になるという前提であれば、C++ parallel algorithmはエクサスパコンにおいて有力な高生産かつ性能可搬な実装手法となり得る。
朝比 祐一; Latu, G.*; Bigot, J.*; Grandgirard, V.*
Proceedings of 2021 International Workshop on Performance, Portability, and Productivity in HPC (P3HPC) (Internet), p.79 - 91, 2021/11
本論文では、性能可搬な運動論的プラズマシミュレーションコードのための最適化手法について論じる。まず、性能可搬ライブラリKokkosと指示行(OpenACC/OpenMP)により、単一実装でCPU、GPUで実行可能な運動論的プラズマシミュレーションコードを開発した。これに最適化を施し、Intelや富士通のCPUおよびNvidia GPUにおいて最適化の効果を評価した。その結果、OpenACC/OpenMPでは1.07倍から1.39倍の性能向上が見られ、Kokkos版では、1.00倍から1.33倍の性能向上が見られた。複数の実装による様々なカーネルの最適化手法の効果を多数のデバイスにおいて調査した本成果は、最適化手法として幅広く利用可能と言える。Kokkosは複数のデータ構造やループ構造を単一コードによって表現することに長けており、CPUとGPU両方において高い性能を発揮するために適したフレームワークであると確認した。
朝比 祐一; Latu, G.*; Bigot, J.*; Grandgirard, V.*
Proceedings of Joint International Conference on Supercomputing in Nuclear Applications + Monte Carlo 2020 (SNA + MC 2020), p.218 - 224, 2020/10
エクサスケール計算機時代には、CPUやGPUの種類を問わずに高性能を発揮する性能可搬性が重要となることが予想される。発表者は、どのような技術を活用すれば運動論的モデルを採用するプラズマ乱流コードの高可搬性実装が可能となるかを調べた。運動論的コードの例として仏国CEAで開発されたGYSELAコードに着目し、当該コードを特徴付ける高次元性(4次元以上)とSemi-Lagrangianスキームといった特徴を抽出したミニアプリケーションを作成した。発表者はミニアプリケーションをOpenACC, OpenMP4.5およびKokkosを用いて並列化し、それぞれの手法の利点,欠点を調査した。OpenACCおよびOpenMP4.5は指示行を挿入することで、Kokkosは高レベルな抽象化を行うことで性能可搬実装を実現する。発表では、生産性,可読性,性能可搬性の観点からそれぞれの手法の利点,欠点を論じる。
朝比 祐一*; Latu, G.*; Bigot, J.*; 前山 伸也*; Grandgirard, V.*; 井戸村 泰宏
Concurrency and Computation; Practice and Experience, 32(5), p.e5551_1 - e5551_21, 2020/03
被引用回数:1 パーセンタイル:11.55(Computer Science, Software Engineering)2つのジャイロ運動論コード、GYSELA, GKVを最新のアクセラレータ環境、Xeon Phi KNL, Tesla P100 GPUに移植した。一台のSkylakeプロセッサーに比べ、KNLにおけるGYSELAの逐次計算カーネルは1.3x、P100 GPUにおけるGKVの逐次計算カーネルは7.4x高速化された。GYSELAとGKVのスケーリングテストをそれぞれ16-512 KNLおよび32-256 P100 GPUで実施し、GYSELAのセミラグランジアンカーネルおよびGKVの畳み込みカーネルにおけるデータ転置通信が主要なボトルネックとなることがわかった。この通信コストを削減するために、これらのコードにパイプライン法およびタスク並列法に基づく通信オーバーラップを実装した。
朝比 祐一; 長谷川 雄太; Padioleau, T.*; Millan, A.*; Bigot, J.*; Grandgirard, V.*; Obrejan, K.*
no journal, ,
一般に、実稼働可能な科学シミュレーションは、計算、通信、ファイルI/Oを含む多くの異なるタスクで構成される。GPUによる計算の高速化に比べて、通信とファイルI/Oは遅くなり、大きなボトルネックになりうる。これらのコストを抑えるためには、これらのタスクを並行して管理することが非常に重要である。本講演では、通信とファイルI/Oのコストをマスクするために、言語標準C++ senders/receiversを採用する。ケーススタディとして、局所アンサンブル変換カルマンフィルタ(LETKF)を用いた2次元乱流シミュレーションコードをC++ senders/receiversを用いて実装する。LETKFでは、模擬観測データはファイルから読み込まれ、その後、MPI通信とGPU上での密行列演算が行われる。このフレームワークによる性能移植が可能なことと、非同期処理による性能向上の効果を実証する。
朝比 祐一; 前山 伸也*; Bigot, J.*; Garbet, X.*; Grandgirard, V.*; 藤井 恵介*; 下川辺 隆史*; 渡邉 智彦*; 井戸村 泰宏; 小野寺 直幸; et al.
no journal, ,
大規模流体シミュレーションのためのin-situデータ解析手法およびdeep learningによる流体シミュレーション結果の代理モデルを開発した。新たに開発したin-situデータ処理手法では、MPIアプリとpythonのポスト処理スクリプトが弱結合される。この手法によってファイルを経由しないポスト処理が可能となり、最大2.7倍の性能向上が見られた。また、多重解像度の流れ場予測を可能にするdeep learning代理モデルを開発した。本モデルでは、十分な予測精度と数値シミュレーションに対する大幅な速度向上を実現した。
朝比 祐一; 前山 伸也*; Bigot, J.*; Garbet, X.*; Grandgirard, V.*; Obrejan, K.*; Padioleau, T.*; 藤井 恵介*; 下川辺 隆史*; 渡邉 智彦*; et al.
no journal, ,
エクサスケール数値計算のための性能可搬性向上に関する研究を紹介する。特にAMD GPUにおけるプラズマコードの性能や、C++標準言語におけるGPUコードの性能評価結果を示す。またdeep learningを用いた流体計算の代理モデルについても紹介する。
朝比 祐一; 前山 伸也*; Bigot, J.*; Garbet, X.*; Grandgirard, V.*; Obrejan, K.*; Padioleau, T.*; 藤井 恵介*; 下川辺 隆史*; 渡邉 智彦*; et al.
no journal, ,
エクサスケール数値計算のための性能可搬性向上に関する研究を紹介する。特にAMD GPUにおけるプラズマコードの性能や、C++標準言語におけるGPUコードの性能評価結果を示す。またdeep learningを用いた流体計算の代理モデルについても紹介する。
朝比 祐一; Latu, G.*; Bigot, J.*; Grandgirard, V.*
no journal, ,
性能可搬な運動論的プラズマシミュレーションコードの実現に向けて、単純化されたミニアプリを開発し、それを性能可搬ライブラリKokkosと指示行によってCPU, GPUで並列実行可能にした。可搬性を高めるため、Kokkosと指示行実装どちらにおいてもコードをCPUとGPUで別途実装することは避け、単一実装でCPU, GPUで並列実行可能とした。開発したミニアプリの性能を富士通A64FX, Nvidia GPUおよびIntel CPUで性能測定した。これらのアーキテクチャはエクサスケールスーパコンピュータにおいて主要な候補になっている。NvidiaやIntelにおいては良好な性能が得られたものの、A64FXにおいてはメモリの間接参照により大幅に性能が大幅劣化することが明らかとなった。講演では、可読性や生産性を高めるためのKokkosや指示行での実装方法についても論じる。
Grandgirard, V.*; 朝比 祐一; Bigot, J.*; Bourne, E.*; Dif-Pradalier, G.*; Donnel, P.*; Garbet, X.*; Ghendrih, P.*
no journal, ,
将来の核融合装置のためにはプラズマ乱流輸送や熱輸送を理解することが重要である。プラズマコアの乱流については非線形の5次元ジャイロ運動論コードによってモデル化可能である。一方で、境界壁付近のプラズマのエッジ領域のモデル化は困難となっている。これらを同時にモデル化するためにはエクサスケール計算機が必須である。エクサスケール計算の準備として、OpenMP4.5taskレベル並列に関する取り組みや、Kokkosによる性能可搬実装のためのコード再設計について説明する。
