


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Asahi, Yuichi; Padioleau, T.*; Latu, G.*; Bigot, J.*; Grandgirard, V.*; Obrejan, K.*
Dai-36-Kai Suchi Ryutai Rikigaku Shimpojiumu Koen Rombunshu (Internet), 8 Pages, 2022/12
We implement a kinetic plasma simulation code with multiple performance portable frameworks and evaluated its performance on Intel Icelake, NVIDIA V100 and A100 GPUs, and AMD MI100 GPU. Relying on the language standard parallelism stdpar and proposed language standard multi-dimensional array support mdspan, we demonstrate a performance portable implementation without harming the readability and productivity. With stdpar, we obtain a good overall performance for a kinetic plasma mini-application in the range of 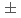 20% to the Kokkos version on Icelake, V100, A100 and MI100. We conclude that stdpar can be a good candidate to develop a performance portable and productive code targeting Exascale era platforms, assuming this programming model will be available on AMD and/or Intel GPUs in the future.
20% to the Kokkos version on Icelake, V100, A100 and MI100. We conclude that stdpar can be a good candidate to develop a performance portable and productive code targeting Exascale era platforms, assuming this programming model will be available on AMD and/or Intel GPUs in the future.
Asahi, Yuichi; Padioleau, T.*; Latu, G.*; Bigot, J.*; Grandgirard, V.*; Obrejan, K.*
Proceedings of 2022 International Workshop on Performance, Portability, and Productivity in HPC (P3HPC) (Internet), p.68 - 80, 2022/11
Times Cited Count:6 Percentile:75.01(Computer Science, Theory & Methods)This paper presents the performance portable implementation of a kinetic plasma simulation code with C++ parallel algorithm to run across multiple CPUs and GPUs. Relying on the language standard parallelism stdpar and proposed language standard multi-dimensional array support mdspan, we demonstrate that a performance portable implementation is possible without harming the readability and productivity. We obtain a good overall performance for a mini-application in the range of 20% to the Kokkos version on Intel Icelake, NVIDIA V100, and A100 GPUs. Our conclusion is that stdpar can be a good candidate to develop a performance portable and productive code targeting the Exascale era platform, assuming this approach will be available on AMD and/or Intel GPUs in the future.
Asahi, Yuichi; Maeyama, Shinya*; Bigot, J.*; Garbet, X.*; Grandgirard, V.*; Obrejan, K.*; Padioleau, T.*; Fujii, Keisuke*; Shimokawabe, Takashi*; Watanabe, Tomohiko*; et al.
no journal, ,
We will demonstrate the performance portable implementation of a kinetic plasma code over CPUs, Nvidia and AMD GPUs. We will also discuss the performance portability of the code with C++ parallel algorithm. Deep learning based surrogate models for fluid simulations will also be demonstrated.
Asahi, Yuichi; Maeyama, Shinya*; Bigot, J.*; Garbet, X.*; Grandgirard, V.*; Obrejan, K.*; Padioleau, T.*; Fujii, Keisuke*; Shimokawabe, Takashi*; Watanabe, Tomohiko*; et al.
no journal, ,
We will demonstrate the performance portable implementation of a kinetic plasma code over CPUs, Nvidia and AMD GPUs. We will also discuss the performance portability of the code with C++ parallel algorithm. Deep learning based surrogate models for fluid simulations will also be demonstrated.
Asahi, Yuichi; Hasegawa, Yuta; Padioleau, T.*; Millan, A.*; Bigot, J.*; Grandgirard, V.*; Obrejan, K.*
no journal, ,
Generally, production-ready scientific simulations consist of many different tasks including computations, communications and file I/O. Compared to the accelerated computations with GPUs, communications and file I/O would be slower which can be major bottlenecks. It is thus quite important to manage these tasks concurrently to suppress these costs. In the present talk, we employ the proposed language standard C++ senders/receivers to mask the costs of communications and file I/O. As a case study, we implement a 2D turbulence simulation code with the local ensemble transform Kalman filter (LETKF) using C++ senders/receivers. In LETKF, the mock observation data are read from files followed by MPI communications and dense matrix operations on GPUs. We demonstrate the performance portable implementation with this framework, while exploiting the performance gain with the introduced concurrency.
