


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Asahi, Yuichi; Onodera, Naoyuki; Hasegawa, Yuta; Shimokawabe, Takashi*; Shiba, Hayato*; Idomura, Yasuhiro
Boundary-Layer Meteorology, 186(3), p.659 - 692, 2023/03
Times Cited Count:2 Percentile:27.46(Meteorology & Atmospheric Sciences)We develop a Transformer-based deep learning model to predict the plume concentrations in the urban area under uniform flow conditions. Our model has two distinct input layers: Transformer layers for sequential data and convolutional layers in convolutional neural networks (CNNs) for image-like data. Our model can predict the plume concentration from realistically available data such as the time series monitoring data at a few observation stations and the building shapes and the source location. It is shown that the model can give reasonably accurate prediction with orders of magnitude faster than CFD simulations. It is also shown that the exactly same model can be applied to predict the source location, which also gives reasonable prediction accuracy.
Onodera, Naoyuki; Idomura, Yasuhiro; Hasegawa, Yuta; Shimokawabe, Takashi*; Aoki, Takayuki*
Keisan Kogaku Koenkai Rombunshu (CD-ROM), 27, 4 Pages, 2022/06
We have developed a wind simulation code named CityLBM to realize wind digital twins. Mesoscale wind conditions are given as boundary conditions in CityLBM by using a nudging data assimilation method. It is found that conventional approaches with constant nudging coefficients fail to reproduce turbulent intensity in long time simulations, where atmospheric stability conditions change significantly. We propose a dynamic parameter optimization method for the nudging coefficient based on a particle filter. CityLBM was validated against plume dispersion experiments in the complex urban environment of Oklahoma City. The nudging coefficient was updated to reduce the error of the turbulent intensity between the simulation and the observation, and the atmospheric boundary layer was reproduced throughout the day.
Asahi, Yuichi; Onodera, Naoyuki; Hasegawa, Yuta; Shimokawabe, Takashi*; Shiba, Hayato*; Idomura, Yasuhiro
Keisan Kogaku Koenkai Rombunshu (CD-ROM), 27, 5 Pages, 2022/06
We have ported the GPU accelerated Lattice Boltzmann Method code "CityLBM" to AMD MI100 GPU. We present the performance of CityLBM achieved on NVIDIA P100, V100, A100 GPUs and AMDMI100 GPU. Using the host to host MPI communications, the performance on MI100 GPU is around 20% better than on V100 GPU. It has turned out that most of the kernels are successfully accelerated except for interpolation kernels for Adaptive Mesh Refinement (AMR) method.
Asahi, Yuichi; Hatayama, Sora*; Shimokawabe, Takashi*; Onodera, Naoyuki; Hasegawa, Yuta; Idomura, Yasuhiro
Proceedings of 2021 IEEE International Conference on Cluster Computing (IEEE Cluster 2021) (Internet), p.686 - 691, 2021/10
Times Cited Count:3 Percentile:70.17(Computer Science, Hardware & Architecture)We develop a convolutional neural network model to predict the multi-resolution steady flow. Based on the state-of-the-art image-to-image translation model pix2pixHD, our model can predict the high resolution flow field from the set of patched signed distance functions. By patching the high resolution data, the memory requirements in our model is suppressed compared to pix2pixHD.
Onodera, Naoyuki; Idomura, Yasuhiro; Hasegawa, Yuta; Nakayama, Hiromasa; Shimokawabe, Takashi*; Aoki, Takayuki*
Boundary-Layer Meteorology, 179(2), p.187 - 208, 2021/05
Times Cited Count:17 Percentile:71.44(Meteorology & Atmospheric Sciences)A plume dispersion simulation code named CityLBM enables a real time simulation for several km by applying adaptive mesh refinement (AMR) method on GPU supercomputers. We assess plume dispersion problems in the complex urban environment of Oklahoma City (JU2003). Realistic mesoscale wind boundary conditions of JU2003 produced by a Weather Research and Forecasting Model (WRF), building structures, and a plant canopy model are introduced to CityLBM. Ensemble calculations are performed to reduce turbulence uncertainties. The statistics of the plume dispersion field, mean and max concentrations show that ensemble calculations improve the accuracy of the estimation, and the ensemble-averaged concentration values in the simulations over 4 km areas with 2-m resolution satisfied factor 2 agreements for 70% of 24 target measurement points and periods in JU2003.
Onodera, Naoyuki; Idomura, Yasuhiro; Hasegawa, Yuta; Shimokawabe, Takashi*; Aoki, Takayuki*
Keisan Kogaku Koenkai Rombunshu (CD-ROM), 26, 3 Pages, 2021/05
We develop a mixed-precision preconditioner for the pressure Poisson equation in a two-phase flow CFD code JUPITER-AMR. The multi-grid (MG) preconditioner is constructed based on the geometric MG method with a three- stage V-cycle, and a cache-reuse SOR (CR-SOR) method at each stage. The numerical experiments are conducted for two-phase flows in a fuel bundle of a nuclear reactor. The MG-CG solver in single-precision shows the same convergence histories as double-precision, which is about 75% of the computational time in double-precision. In the strong scaling test, the MG-CG solver in single-precision is accelerated by 1.88 times between 32 and 96 GPUs.
Asahi, Yuichi; Hatayama, Sora*; Shimokawabe, Takashi*; Onodera, Naoyuki; Hasegawa, Yuta; Idomura, Yasuhiro
Keisan Kogaku Koenkai Rombunshu (CD-ROM), 26, 4 Pages, 2021/05
We develop a convolutional neural network model to predict the multi-resolution steady flow. Based on the state-of-the-art image-to-image translation model Pix2PixHD, our model can predict the high resolution flow field from the signed distance function. By patching the high resolution data, the memory requirements in our model is suppressed compared to Pix2PixHD.
Onodera, Naoyuki; Idomura, Yasuhiro; Hasegawa, Yuta; Yamashita, Susumu; Shimokawabe, Takashi*; Aoki, Takayuki*
Proceedings of International Conference on High Performance Computing in Asia-Pacific Region (HPC Asia 2021) (Internet), p.120 - 128, 2021/01
Times Cited Count:0 Percentile:0.00(Computer Science, Hardware & Architecture)We develop a multigrid preconditioned conjugate gradient (MG-CG) solver for the pressure Poisson equation in a two-phase flow CFD code JUPITER. The MG preconditioner is constructed based on the geometric MG method with a three-stage V-cycle, and a RB-SOR smoother and its variant with cache-reuse optimization (CR-SOR) are applied at each stage. The numerical experiments are conducted for two-phase flows in a fuel bundle of a nuclear reactor. The MG-CG solvers with the RB-SOR and CR-SOR smoothers reduce the number of iterations to less than 15% and 9% of the original preconditioned CG method, leading to 3.1- and 5.9-times speedups, respectively. The obtained performance indicates that the MG-CG solver designed for the block-structured grid is highly efficient and enables large-scale simulations of two-phase flows on GPU based supercomputers.
Onodera, Naoyuki; Idomura, Yasuhiro; Asahi, Yuichi; Hasegawa, Yuta; Shimokawabe, Takashi*; Aoki, Takayuki*
Dai-34-Kai Suchi Ryutai Rikigaku Shimpojiumu Koen Rombunshu (Internet), 2 Pages, 2020/12
We develop a multigrid preconditioned conjugate gradient (MG-CG) solver for the pressure Poisson equation in a two-phase flow CFD code JUPITER. The code is written in C++ and CUDA to keep the portability on multi-platforms. The main kernels of the CG solver achieve reasonable performance as 0.4 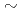 0.75 of the roofline performances, and the performances of the MG-preconditioner are also reasonable on NVIDIA GPU and Intel CPU. However, the performance degradation of the SpMV kernel on ARM is significant. It is confirmed that the optimization does not work if any functions are included in the loop.
0.75 of the roofline performances, and the performances of the MG-preconditioner are also reasonable on NVIDIA GPU and Intel CPU. However, the performance degradation of the SpMV kernel on ARM is significant. It is confirmed that the optimization does not work if any functions are included in the loop.
Onodera, Naoyuki; Idomura, Yasuhiro; Ali, Y.*; Yamashita, Susumu; Shimokawabe, Takashi*; Aoki, Takayuki*
Proceedings of Joint International Conference on Supercomputing in Nuclear Applications + Monte Carlo 2020 (SNA + MC 2020), p.210 - 215, 2020/10
This paper presents a GPU-based Poisson solver on a block-based adaptive mesh refinement (block-AMR) framework. The block-AMR method is essential for GPU computation and efficient description of the nuclear reactor. In this paper, we successfully implement a conjugate gradient method with a state-of-the-art multi-grid preconditioner (MG-CG) on the block-AMR framework. GPU kernel performance was measured on the GPU-based supercomputer TSUBAME3.0. The bandwidth of a vector-vector sum, a matrix-vector product, and a dot product in the CG kernel gave good performance at about 60% of the peak performance. In the MG kernel, the smoothers in a three-stage V-cycle MG method are implemented using a mixed precision RB-SOR method, which also gave good performance. For a large-scale Poisson problem with 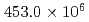 cells, the developed MG-CG method reduced the number of iterations to less than 30% and achieved
cells, the developed MG-CG method reduced the number of iterations to less than 30% and achieved 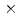 2.5 speedup compared with the original preconditioned CG method.
2.5 speedup compared with the original preconditioned CG method.
Onodera, Naoyuki; Idomura, Yasuhiro; Ali, Y.*; Shimokawabe, Takashi*; Aoki, Takayuki*
Keisan Kogaku Koenkai Rombunshu (CD-ROM), 25, 4 Pages, 2020/06
We have developed the stencil-based CFD code JUPITER for simulating three-dimensional multiphase flows. A GPU-accelerated Poisson solver based on the preconditioned conjugate gradient (P-CG) method with a multigrid preconditioner was developed for the JUPITER with block-structured AMR mesh. All Poisson kernels were implemented using CUDA, and the GPU kernel function is well tuned to achieve high performance on GPU supercomputers. The developed multigrid solver shows good convergence of about 1/7 compared with the original P-CG method, and 3 speed up is achieved with strong scaling test from 8 to 216 GPUs on TSUBAME 3.0.
Onodera, Naoyuki; Idomura, Yasuhiro; Ali, Y.*; Shimokawabe, Takashi*
Proceedings of 9th Workshop on Latest Advances in Scalable Algorithms for Large-Scale Systems (ScalA 2018) (Internet), p.9 - 16, 2018/11
Times Cited Count:10 Percentile:92.71(Computer Science, Theory & Methods)We develop a communication reduced multi-time- step (CRMT) algorithm for a Lattice Boltzmann method (LBM) based on a block-structured adaptive mesh refinement (AMR). This algorithm is based on the temporal blocking method, and can improve computational efficiency by replacing a communication bottleneck with additional computation. The proposed method is implemented on an extreme scale airflow simulation code CityLBM, and its impact on the scalability is tested on GPU based supercomputers, TSUBAME and Reedbush. Thanks to the CRMT algorithm, the communication cost is reduced by 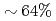 , and weak and strong scalings are improved up to
, and weak and strong scalings are improved up to 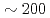 GPUs. The obtained performance indicates that real time airflow simulations for about 2km square area with the wind speed of
GPUs. The obtained performance indicates that real time airflow simulations for about 2km square area with the wind speed of 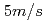 is feasible using 1m resolution.
is feasible using 1m resolution.
Shimokawabe, Takashi*; Endo, Toshio*; Onodera, Naoyuki; Aoki, Takayuki*
Proceedings of 2017 IEEE International Conference on Cluster Computing (IEEE Cluster 2017) (Internet), p.525 - 529, 2017/09
Stencil-based applications such as CFD have succeeded in obtaining high performance on GPU supercomputers. The problem sizes of these applications are limited by the GPU device memory capacity, which is typically smaller than the host memory. On GPU supercomputers, a locality improvement technique using temporal blocking method with memory swapping between host and device enables large computation beyond the device memory capacity. Our high-productivity stencil framework automatically applies temporal blocking to boundary exchange required for stencil computation and supports automatic memory swapping provided by a MPI/CUDA wrapper library. The framework-based application for the airflow in an urban city maintains 80% performance even with the twice larger than the GPU memory capacity and have demonstrated good weak scalability on the TSUBAME 2.5 supercomputer.
Onodera, Naoyuki; Idomura, Yasuhiro; Asahi, Yuichi; Hasegawa, Yuta; Shimokawabe, Takashi*; Aoki, Takayuki*
no journal, ,
This paper presents performance studies of a multigrid (MG) Poisson solver on a block-structured adaptive mesh refinement (block-AMR) method on CPU and GPU supercomputers. The block-AMR method is efficient solutions of the nuclear reactor which is composed of complicated structures. We implement a three-stage V-cycle MG method and the calculation is accelerated by using a mixed precision techniques. For a large-scale Poisson problem with 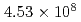 cells, the developed MG-CG method reduced the number of iterations to less than 30% and achieved 2 times speedup compared with the original preconditioned CG method on the GPU-supercomputer TSUBAME. This kind of performance studies are useful for designing advanced preconditioners in terms of robustness, computational precision, thread parallelization, and cache size on each architecture.
cells, the developed MG-CG method reduced the number of iterations to less than 30% and achieved 2 times speedup compared with the original preconditioned CG method on the GPU-supercomputer TSUBAME. This kind of performance studies are useful for designing advanced preconditioners in terms of robustness, computational precision, thread parallelization, and cache size on each architecture.
Hatayama, Sora*; Shimokawabe, Takashi*; Onodera, Naoyuki
no journal, ,
We propose a prediction method for large-scale simulation results by dividing the input geometry into multiple parts and applying a single small neural network to each part in parallel. The constructed model predicts a two-dimensional velocity field using a signed distance function as input. In addition, we divide a large area into multiple regions and the prediction is iteratively performed for each region until convergence. Finally, we confirmed that the velocity fields of multiple regions are reproduced by using a boundary exchange method.
Onodera, Naoyuki; Idomura, Yasuhiro; Hasegawa, Yuta; Nakayama, Hiromasa; Shimokawabe, Takashi*; Aoki, Takayuki*
no journal, ,
This paper presents a novel data assimilation method in realistic turbulent boundary layer simulations for the realization of a wind digital twin. We have developed a plume dispersion simulation code named CityLBM based on a lattice Boltzmann method. CityLBM enables a real time ensemble simulation for several km square area by applying locally mesh-refinement method on GPU supercomputers. Mesoscale wind boundary conditions produced by a Weather Research and Forecasting Model are given as boundary conditions in CityLBM by using a nudging data assimilation method. In this study, we propose a dynamic nudging data assimilation method, where a particle filter optimizes the nudging coefficient based on the observation data. This approach gave reasonable agreements in vertical profiles of the wind speed, the wind direction, and the turbulent intensity compared to the observation data throughout the day, and enabled all-day simulations, where atmospheric conditions change significantly.
Onodera, Naoyuki; Hasegawa, Yuta; Idomura, Yasuhiro; Asahi, Yuichi; Kawamura, Takuma; Ina, Takuya; Shimomura, Kazuya; Inagaki, Atsushi*; Suzuki, Shinichi*; Hirano, Kohin*; et al.
no journal, ,
Wind prediction based on digital twin is a promising technology that can contribute to the construction of new social infrastructures, including applications to smart city design and operation. In this poster presentation, we will introduce wind simulations based on data assimilation with observations and mesoscale meteorological data for the realization of a digital twin of wind conditions in urban areas.
Onodera, Naoyuki; Shimokawabe, Takashi*; Idomura, Yasuhiro; Kawamura, Takuma; Hasegawa, Yuta; Ina, Takuya; Inagaki, Atsushi*; Hirano, Kohin*; Shimose, Kenichi*; Oda, Ryoko*; et al.
no journal, ,
The project goal is to realize real-time wind prediction in urban areas by assimilating observed data into real-time wind simulations on GPU supercomputers. In FY2023, a data assimilation method based on the Local Ensemble Transform Kalman Filter (LETKF) was applied to CityLBM in order to reproduce local wind conditions with high accuracy. We validated the data assimilation method for two-dimensional forced isotropic turbulence. It was confirmed that the LETKF with 64 ensembles provides the same levels of accuracy with 1/16th of the coarse observation points compared to the nudging method. In addition, it was confirmed that the application of LETKF can reproduce the phase of the Kalman vortex with high accuracy in the verification of the flow around a three-dimensional square cylinder.
Sugihara, Kenta; Aoki, Takayuki*; Onodera, Naoyuki; Idomura, Yasuhiro; Kawamura, Takuma; Shimokawabe, Takashi*; Ina, Takuya; Yamashita, Susumu
no journal, ,
To improve the interface model for nuclear gas-liquid two-phase flow analysis using an exa-scale supercomputer, the Phase Field variables in the bubble rise calculation were optimised, the bubble inflow conditions were improved, and the interface capture method using the Multi-Phase Field method was developed. As a basic verification, the developed method was applied to bubble flow analysis in a circular tube, and the void fraction distribution and mean velocity distribution were compared with experimental results, which showed good quantitative agreement.
Onodera, Naoyuki; Aoki, Takayuki*; Idomura, Yasuhiro; Yamashita, Susumu; Kawamura, Takuma; Asahi, Yuichi; Ina, Takuya; Hasegawa, Yuta; Sugihara, Kenta; Shimokawabe, Takashi*; et al.
no journal, ,
no abstracts in English
