


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Yamasaki, Satoshi*; Terada, Toru*; Kono, Hidetoshi; Shimizu, Kentaro*; Sarai, Akinori*
Nucleic Acids Research, 40(17), p.e129_1 - e129_7, 2012/09
Times Cited Count:20 Percentile:44.63(Biochemistry & Molecular Biology)Arimori, Takao; Tamaoki, Haruhiko*; Nakamura, Teruya*; Kamiya, Hiroyuki*; Ikemizu, Shinji*; Takagi, Yasumitsu*; Ishibashi, Toru*; Harashima, Hideyoshi*; Sekiguchi, Mutsuo*; Yamagata, Yuriko*
Nucleic Acids Research, 39(20), p.8972 - 8983, 2011/11
Times Cited Count:26 Percentile:53.25(Biochemistry & Molecular Biology)Yamasaki, Satoshi*; Terada, Toru*; Shimizu, Kentaro*; Kono, Hidetoshi; Sarai, Akinori*
Nucleic Acids Research, 37(20), p.e135_1 - e135_9, 2009/09
Times Cited Count:7 Percentile:14.56(Biochemistry & Molecular Biology)Bellon, S.*; Shikazono, Naoya; Cunniffe, S. M. T.*; Lomax, M.*; O'Neill, P.*
Nucleic Acids Research, 37(13), p.4430 - 4440, 2009/07
Times Cited Count:50 Percentile:70.92(Biochemistry & Molecular Biology)Ishida, Hisashi; Kono, Hidetoshi
Research Advances in Nucleic Acids Research, p.19 - 34, 2009/03
Yamasaki, Chisato*; Murakami, Katsuhiko*; Fujii, Yasuyuki*; Sato, Yoshiharu*; Harada, Erimi*; Takeda, Junichi*; Taniya, Takayuki*; Sakate, Ryuichi*; Kikugawa, Shingo*; Shimada, Makoto*; et al.
Nucleic Acids Research, 36(Database), p.D793 - D799, 2008/01
Times Cited Count:52 Percentile:70.56(Biochemistry & Molecular Biology)Here we report the new features and improvements in our latest release of the H-Invitational Database, a comprehensive annotation resource for human genes and transcripts. H-InvDB, originally developed as an integrated database of the human transcriptome based on extensive annotation of large sets of fulllength cDNA (FLcDNA) clones, now provides annotation for 120 558 human mRNAs extracted from the International Nucleotide Sequence Databases (INSD), in addition to 54 978 human FLcDNAs, in the latest release H-InvDB. We mapped those human transcripts onto the human genome sequences (NCBI build 36.1) and determined 34 699 human gene clusters, which could define 34 057 protein-coding and 642 non-protein-coding loci; 858 transcribed loci overlapped with predicted pseudogenes.
Kono, Hidetoshi; Yuasa, Tomo*; Nishiue, Shinya*; Yura, Kei
Nucleic Acids Research, 36(Database), p.D409 - D413, 2008/01
Times Cited Count:18 Percentile:33.71(Biochemistry & Molecular Biology)We have developed coliSNP, a database server (http://yayoi.kansai.jaea.go.jp/colisnp) that maps non-synonymous single nucleotide polymorphisms (nsSNPs) on the three-dimensional (3D) structure of proteins. Once a week, the SNP data from the dbSNP database and the protein structure data from the Protein Data Bank (PDB) are downloaded, and the correspondence of the two data sets is automatically tabulated in the coliSNP database. Given an amino acid sequence, protein name or PDB ID, the server will immediately provide known nsSNP information, including the amino acid mutation caused by the nsSNP, the solvent accessibility, the secondary structure and the flanking residues of the mutated residue in a single page. The position of the nsSNP within the amino acid sequence and on the 3D structure of the protein can also be observed. The database provides key information with which to judge whether an observed nsSNP critically affects protein function and/or stability. As far as we know, this is the only web-based nsSNP database that automatically compiles SNP and protein information in a concise manner.
Fujii, Satoshi*; Kono, Hidetoshi; Takenaka, Shigeori*; Go, Nobuhiro; Sarai, Akinori*
Nucleic Acids Research, 35(18), p.6063 - 6074, 2007/09
Times Cited Count:105 Percentile:86.91(Biochemistry & Molecular Biology)Proteins recognize specific DNA sequences not only through direct contact between amino acids and bases, but also indirectly based on the sequence-dependent conformation and deformability of the DNA (indirect readout). We used molecular dynamics simulations to analyze the sequence-dependent DNA conformations of all 136 possible tetrameric sequences sandwiched between CGCG sequences. The deformability of dimeric steps obtained by the simulations is consistent with that by the crystal structures. The simulation results further showed that the conformation and deformability of the tetramers can highly depend on the flanking base-pairs. The conformations of xATx tetramers show the most rigidity and are not affected by the flanking base-pairs and the xYRx show by contrast the greatest flexibility and change their conformations depending on the base-pairs at both ends, suggesting tetramers with the same central dimer can show different deformabilities. These results suggest that analysis of dimeric steps alone may overlook some conformational features of DNA and provide insight into the mechanism of indirect readout during protein-DNA recognition. Moreover, the sequence dependence of DNA conformation and deformability may be used to estimate the contribution of indirect readout to the specificity of protein-DNA recognition as well as nucleosome positioning and large-scale behavior of nucleic acids.
Kim, O. T. P.*; Yura, Kei; Go, Nobuhiro
Nucleic Acids Research, 34(22), p.6450 - 6460, 2006/12
Times Cited Count:101 Percentile:85.35(Biochemistry & Molecular Biology)Protein-RNA interactions play essential roles in a number of regulatory mechanisms for gene expression such as RNA splicing, transport, translation and post-transcriptional control. As the number of available protein-RNA complex three-dimensional (3D) structures has increased, it is now possible to statistically examine protein-RNA interactions based on 3D structures. We performed computational analyses of 86 representative protein-RNA complexes retrieved from the Protein Data Bank. Interface residue propensity was calculated for each amino acid residue type (residue singlet interface propensity). In addition to the residue singlet propensity, we introduce a new residue doublet interface propensity. The residue doublet interface propensity contains much more information than the sum of two singlet propensities alone. The prediction of the RNA interface using the two types of propensities plus a position-specific multiple sequence profile can achieve a specificity of about 80 percent.
Shikazono, Naoya; Pearson, C.*; O'Neill, P.*; Thacker, J.*
Nucleic Acids Research, 34(13), p.3722 - 3730, 2006/08
Times Cited Count:60 Percentile:71.84(Biochemistry & Molecular Biology)no abstracts in English
Ahmad, S.*; Kono, Hidetoshi; Ara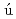 zo-Bravo, M. J.*; Sarai, Akinori*
zo-Bravo, M. J.*; Sarai, Akinori*
Nucleic Acids Research, 34(Suppl.2), p.W124 - W127, 2006/07
Times Cited Count:31 Percentile:48.95(Biochemistry & Molecular Biology)no abstracts in English
Takeda, Junichi*; Suzuki, Yutaka*; Nakao, Mitsuteru*; Barrero, R. A.*; Koyanagi, Kanako*; Jin, L.*; Motono, Chie*; Hata, Hiroko*; Isogai, Takao*; Nagai, Keiichi*; et al.
Nucleic Acids Research, 34(14), p.3917 - 3928, 2006/00
Times Cited Count:35 Percentile:53.27(Biochemistry & Molecular Biology)We report the first genome-wide identification and characterization of alternative splicing in human gene transcripts based on analysis of the full-length cDNAs. Applying both manual and computational analyses for 56 419 completely sequenced and precisely annotated full-length cDNAs selected for the H-Invitational human transcriptome annotation meetings, we identified 6877 alternative splicing genes with 18 297 different alternative splicing variants. A total of 37 670 exons were involved in these alternative splicing events. The encoded protein sequences were affected in 6005 of the 6877 genes. Notably, alternative splicing affected protein motifs in 3015 genes, subcellular localizations in 2982 genes and transmembrane domains in 1348 genes. Genome-wide annotations of alternative splicing, relying on full-length cDNAs, should lay firm groundwork for exploring in detail the diversification of protein function which is mediated by the alternative splicing variants.
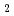 observed by neutron diffraction measurements
observed by neutron diffraction measurementsArai, Shigeki; Chatake, Toshiyuki*; Ohara, Takashi; Kurihara, Kazuo; Tanaka, Ichiro*; Suzuki, Nobuhiro*; Fujimoto, Zui*; Mizuno, Hiroshi*; Niimura, Nobuo
Nucleic Acids Research, 33(9), p.3017 - 3024, 2005/05
Times Cited Count:94 Percentile:82.51(Biochemistry & Molecular Biology)It has long been suspected that the structure and function of a DNA duplex can be strongly dependent on its degree of hydration. By neutron diffraction experiments, we have succeeded in determining most of the hydrogen (H) and deuterium (D) atomic positions in the d(CCATTAATGG) duplex. Moreover, the D positions in 27 DO molecules have been determined. In particular, the complex water network in the minor groove has been observed in detail. By a combined structural analysis using 2.0 Å resolution X-ray and 3.0 Å resolution neutron data, it is clear that the spine of hydration is built up, not only by a simple hexagonal hydration pattern (as reported in prior X-ray studies), but also by many other water bridges hydrogen-bonded to the DNA strands. The complexity of the hydration pattern in the minor groove is derived from an extraordinary variety of orientations displayed by the water molecules.
Yamaguchi, Akihiro*; Iwadate, Mitsuo*; Suzuki, Eiichiro*; Yura, Kei; Kawakita, Shigetsune*; Umeyama, Hideaki*; Go, Michiko*
Nucleic Acids Research, 31(1), p.463 - 468, 2003/01
Times Cited Count:15 Percentile:24.78(Biochemistry & Molecular Biology)Enlarged FAMSBASE is a relational database of comparative protein structure models for the whole genome of 41 species, presented in the GTOP database. The models are calculated by FAMS, Full Automatic Modeling System. Enlarged FAMSBASE provides a wide range of query keys, such as name of ORF (open reading frame), ORF keywords, PDB ID, PDB heterogen atoms, and sequence similarity. Heterogen atoms in PDB include cofactors, ligands, and other factors that interact with proteins, and are a good starting point for analyzing interactions between proteins and other molecules. The data may also work as a template for drug design. The present number of ORFs with protein 3D models in FAMSBASE is 183,805, and the database includes an average of three models for each ORF. FAMSBASE is available at http://famsbase.bio.nagoya-u.ac.jp/famsbase/.
