


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Hasegawa, Yuta; Aoki, Takayuki*; Kobayashi, Hiromichi*; Idomura, Yasuhiro; Onodera, Naoyuki
Parallel Computing, 108, p.102851_1 - 102851_12, 2021/12
Times Cited Count:6 Percentile:51.00(Computer Science, Theory & Methods)The aerodynamics simulation code based on the lattice Boltzmann method (LBM) using forest-of-octrees-based block-structured local mesh refinement (LMR) was implemented, and its performance was evaluated on GPU-based supercomputers. We found that the conventional Space-Filling-Curve-based (SFC) domain partitioning algorithm results in costly halo communication in our aerodynamics simulations. Our new tree cutting approach improved the locality and the topology of the partitioned sub-domains and reduced the communication cost to one-third or one-fourth of the original SFC approach. In the strong scaling test, the code achieved maximum 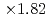 speedup at the performance of 2207 MLUPS (mega- lattice update per second) on 128 GPUs. In the weak scaling test, the code achieved 9620 MLUPS at 128 GPUs with 4.473 billion grid points, while the parallel efficiency was 93.4% from 8 to 128 GPUs.
speedup at the performance of 2207 MLUPS (mega- lattice update per second) on 128 GPUs. In the weak scaling test, the code achieved 9620 MLUPS at 128 GPUs with 4.473 billion grid points, while the parallel efficiency was 93.4% from 8 to 128 GPUs.
Yamada, Susumu; Machida, Masahiko; Imamura, Toshiyuki*
Parallel Computing; Technology Trends, p.105 - 113, 2020/00
Times Cited Count:1 Percentile:29.37(Computer Science, Hardware & Architecture)no abstracts in English
Yamada, Susumu; Imamura, Toshiyuki*; Machida, Masahiko
Parallel Computing is Everywhere, p.27 - 36, 2018/00
no abstracts in English
Yamada, Susumu; Imamura, Toshiyuki*; Machida, Masahiko
Parallel Computing; On the Road to Exascale, p.361 - 369, 2016/00
Times Cited Count:1 Percentile:40.54(Computer Science, Hardware & Architecture)no abstracts in English
Maeyama, Shinya; Watanabe, Tomohiko*; Idomura, Yasuhiro; Nakata, Motoki; Nunami, Masanori*; Ishizawa, Akihiro*
Parallel Computing, 49, p.1 - 12, 2015/11
Times Cited Count:7 Percentile:49.77(Computer Science, Theory & Methods)Yamada, Susumu; Imamura, Toshiyuki*; Machida, Masahiko
Parallel Computing; Accelerating Computational Science and Engineering (CSE), p.427 - 436, 2014/03
no abstracts in English
Kushida, Noriyuki
Proceedings of 20th Euromicro International Conference on Parallel, Distributed and Network-Based Computing (PDP 2012), p.7 - 8, 2012/02
Infrasound wave propagation simulation and radioactive transfer simulation were accelerated with GPGPU and multicore processors. These simulation codes supports CTBTO mission that detects nuclear test. Since these applications have been carried out on an isolated workstation, high-performance computing units, like GPGPU and multicore processors, are helpful for more accurate simulation. As a result, we achieve 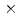 18.3 speedup for infrasound that enables us to run more reliable method than the other simpler method one the same calculation speed, and we achieve the Northern Hemisphere radioactive transfer simulation that have been virtually impossible so far.
18.3 speedup for infrasound that enables us to run more reliable method than the other simpler method one the same calculation speed, and we achieve the Northern Hemisphere radioactive transfer simulation that have been virtually impossible so far.
Kushida, Noriyuki
Proceedings of 19th Euromicro International Conference on Parallel, Distributed and Network-Based Computing (PDP 2011), p.401 - 408, 2011/02
I introduced a new implementation of the finite element method (FEM) that is suitable for the cell processors. Since the cell processors have a far greater performance and low byte per flop (B/F) rate than traditional scalar processors, I reduced the amount of memory transfer and employed memory access times hiding technique. The amount of memory transfer was reduced by accepting additional floating-point operations by not storing data if it was required repeatedly. In this study, such memory access reduction was applied to conjugate gradient method (CG). In order to achieve memory access reduction in CG, element-wise computation was employed for avoiding global coefficient matrices that causes frequent memory access. Moreover, all data transfer times were concealed behind the calculation time. As a result, my new implementation performed 10 times better than a traditional implementation that run on a PPU.
Kushida, Noriyuki; Takemiya, Hiroshi; Tokuda, Shinji*
Proceedings of 18th Euromicro International Conference on Parallel, Distributed and Network-Based Computing (PDP 2010), p.482 - 488, 2010/02
In this study, we developed a high speed eigenvalue solver that is the necessity of plasma stability analysis system for International Thermo-nuclear Experimental Reactor (ITER) on Cell cluster system. According to our estimation, the most time consuming part of analysis system is eigensolver. However, current supercomputer is not applicable for such instantaneous calculation, because the overhead of network communication becomes dominant. Therefore, we employ Cell cluster system, whose processor has higher performance than current supercomputer, because we can obtain sufficient processing power with small number of processors. Furthermore, we developed novel eigenvalue solver with the consideration of hierarchical architecture of Cell cluster Finally, we succeeded to solve the block tridiagonal Hermitian matrix, which had 1024 diagonal blocks and the size of each block was 128 128 within a second.
Yamada, Tomonori
Parallel, Distributed and Grid Computing for Engineering, p.439 - 454, 2009/04
An overview of the seismic simulation of nuclear power plants conducted in Japan Atomic Agency and the reduction of its computation cost are presented. The importance of nuclear power generation for ensuring national energy security is widely acknowledged. The seismic safety of nuclear power plants has attracted considerable attention after the introduction of new regulatory guidelines for the seismic design of nuclear power plants in Japan and also after several recent strong earthquakes.
Kim, G.; Suzuki, Yoshio; Teshima, Naoya; Nishida, Akemi; Yamada, Tomonori; Araya, Fumimasa; Takemiya, Hiroshi; Nakajima, Norihiro; Kondo, Makoto
Proceedings of 1st International Conference on Parallel, Distributed and Grid Computing for Engineering (PARENG 2009) (CD-ROM), 12 Pages, 2009/04
Yamada, Susumu; Okumura, Masahiko; Machida, Masahiko
Proceedings of IASTED International Conference on Parallel and Distributed Computing and Networks (PDCN 2008), p.175 - 180, 2008/02
The Density Matrix Renormalization Group (DMRG) method is widely used by computational physicists as a high accuracy tool to explore the ground state of large quantum lattice systems. However, the reliable results by DMRG are limited only for 1-D or two-leg ladder models in spite of a great demand for 2-D system. The reason is that the direct extension to 2-D requires an enormous memory space while the technical extension based on 1-D algorithm does not keep the accuracy in 1-D systems. Therefore, we parallelize the direct 2-D DMRG code on a large-scale supercomputer and examine the accuracy and the performance for typical lattice models, i.e., Heisenberg and Hubbard models. The parallelization is mainly made on the multiplication of the Hamiltonian matrix and vectors. We find that the parallelization efficiency, i.e., the speed up ratio with increasing the number of CPU, shows a good one as the number of states kept increases. This result is promising for future 2-D parallel DMRG simulations.
Yamada, Susumu; Imamura, Toshiyuki*; Machida, Masahiko
Proceedings of 23rd IASTED International Multi-Conference on Parallel and Distributed Computing and Networks (PDCN 2005), p.638 - 643, 2005/02
no abstracts in English
; Hirayama, Toshio; ; Hayashi, Takuya*; Kasahara, Hironori*
Int. Conf. on Supercomputing,Workshop 1;Scheduling Algorithms for Parallel-Distributed Computing, p.63 - 69, 1999/00
no abstracts in English
Imamura, Toshiyuki; Tokuda, Shinji
Proceedings of IASTED International Conference on Parallel and Distributed Computing and Systems, p.583 - 588, 1999/00
no abstracts in English
Int. Symp. on Parallel Computing in Engineering and Science, 0, 10 Pages, 1997/00
no abstracts in English
Scientific Computing in Object-Oriented Parallel Environments, p.211 - 217, 1997/00
no abstracts in English
; ; Masukawa, Fumihiro
Proc. of the 3rd Parallel Computing Workshop; PCW 94, 0, p.P2.G.1 - P2.G.9, 1994/00
no abstracts in English
; Masukawa, Fumihiro;
Proc. of the 2nd Parallel Computing Workshop; PCW 93, p.P2-P-1 - P2-P-5, 1993/00
no abstracts in English
Takeda, Tatsuoki; Tani, Keiji; Tsunematsu, Toshihide; Kishimoto, Yasuaki; ; ;
Parallel Computing, 18, p.743 - 765, 1992/00
Times Cited Count:2 Percentile:47.40(Computer Science, Theory & Methods)no abstracts in English
Masukawa, Fumihiro; ; Naito, Yoshitaka; ;
Proc. of the 1st Annual Users Meeting of Fujitsu Parallel Computing Research Facilities, p.P1-A-1 - P1-A-8, 1992/00
no abstracts in English
