


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
井戸村 泰宏; 伊奈 拓也*; Ali, Y.*; 今村 俊幸*
Proceedings of International Conference for High Performance Computing, Networking, Storage, and Analysis (SC 2020) (Internet), p.1318 - 1330, 2020/11
被引用回数:2 パーセンタイル:46.63(Computer Science, Information Systems)5次元ジャイロ運動論モデルに基づく次世代核融合実験炉ITERのマルチスケールfull-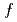 シミュレーションは核融合科学において最も計算コストが大きい問題の一つである。本研究では、新しい混合精度省通信クリロフ法を用いてジャイロ運動論的トロイダル5次元オイラーコードGT5Dを高速化した。演算加速環境における大域的集団通信のボトルネックを省通信クリロフ法によって解決した。これに加えて、A64FXにおいて新たにサポートされたFP16SIMD演算を用いて設計された新しいFP16前処理により、反復(袖通信)の回数と計算コストの両方を削減した。富岳とSummitにおける1,440CPU/GPUを用いた1,000億格子のITER規模シミュレーションに対して、提案手法の処理性能は従来の非省通信クリロフ法に比べてそれぞれ2.8倍, 1.9倍高速化され、5,760CPU/GPUまで良好な強スケーリングを示した。
シミュレーションは核融合科学において最も計算コストが大きい問題の一つである。本研究では、新しい混合精度省通信クリロフ法を用いてジャイロ運動論的トロイダル5次元オイラーコードGT5Dを高速化した。演算加速環境における大域的集団通信のボトルネックを省通信クリロフ法によって解決した。これに加えて、A64FXにおいて新たにサポートされたFP16SIMD演算を用いて設計された新しいFP16前処理により、反復(袖通信)の回数と計算コストの両方を削減した。富岳とSummitにおける1,440CPU/GPUを用いた1,000億格子のITER規模シミュレーションに対して、提案手法の処理性能は従来の非省通信クリロフ法に比べてそれぞれ2.8倍, 1.9倍高速化され、5,760CPU/GPUまで良好な強スケーリングを示した。
松本 和也*; 井戸村 泰宏; 伊奈 拓也*; 真弓 明恵; 山田 進
Journal of Supercomputing, 75(12), p.8115 - 8146, 2019/12
被引用回数:2 パーセンタイル:21.08(Computer Science, Hardware & Architecture)ジャイロ運動論的トロイダル5次元オイラーコードGT5Dにおける反復法線形ソルバの性能向上に向けて省通信一般化最小残差法(CA-GMRES)をCPU-GPUハイブリッドクラスタで実装した。CA-GMRESに加え、計算量を削減するために我々が提案した修正版CA-GMRES(M-CA-GMRES)の実装と評価も行った。本研究から、集団通信回数の最小化と密行列積演算による高効率演算というCA-GMRESの利点が実証された。性能評価は1ノードあたりNVIDIA Tesla P100 GPU4台を搭載したReedbush-L GPUクラスタで実施した。この結果、M-CA-GMRESによりCA-GMRES, 一般化共役残差法(GCR), GMRESに比べてそれぞれ1.09x, 1.22x, 1.50xの高速化が示された。
Ali, Y.*; 小野寺 直幸; 井戸村 泰宏; 伊奈 拓也*; 今村 俊幸*
Proceedings of 10th Workshop on Latest Advances in Scalable Algorithms for Large-Scale Systems (ScalA 2019), p.1 - 8, 2019/11
被引用回数:11 パーセンタイル:93.84(Computer Science, Theory & Methods)大規模線形問題の反復法ソルバはCFDコードで共通に用いられる。前処理付共役勾配(P-CG)法は最も広く用いられている反復法の一つである。しかしながら、P-CG法では、特に演算加速環境において、大域的集団通信が重要なボトルネックとなる。この問題を解決するために、省通信版のP-CG法がますます重要になっている。本論文では多相CFDコードJUPITERにおけるP-CG法と前処理付チェビシェフ基底省通信CG(P-CBCG)法を最新のV100GPUに移植する。全てのGPUカーネルは高度に最適化され約90%のルーフライン性能を達成し、ブロックヤコビ前処理はGPUの高い演算性能を引き出すように再設計し、さらに残された袖通信のボトルネックは通信と計算のオーバーラップによって回避した。P-CG法とP-CBCG法の全体性能は大域的集団通信と袖通信の省通信特性によって左右され、GPUあたりのノード間通信帯域が重要となることが示された。開発したGPUソルバはKNLにおける以前のCPUソルバの2倍に加速され、Summitにおいて7,680GPUまで良好な強スケーリングを達成した。
井戸村 泰宏
no journal, ,
省通信アルゴリズムは演算加速と相対的に低い通信バンド幅で特徴付けられる将来のエクサスケール計算機における大規模流体シミュレーションに向けたキーテクノロジーになっている。この通信ボトルネックを解決するために、5次元核融合プラズマ乱流コードGT5Dや3次元多相熱流動解析コードJUPITERといった大規模原子力シミュレーションにおいて2種類の省通信疎行列ソルバを開発した。一つは複数の基底ベクトルの生成と直交化を一度に行う省通信クリロフ法である。本手法により、従来のクリロフ法では反復毎に必要となっていたAll_Reduce通信のボトルネックを回避できる。もう一つの手法は、収束特性の改善により反復回数とAll_Reduce通信回数を削減する省通信マルグリット法である。この手法では混合精度のマルチグリッド実装によってさらに演算と通信を削減する。これらの省通信ソルバによりGT5DとJUPITERの性能が大幅に向上し、8,208台のKNLから構成されるOakforest-PACSにおいて全系まで強スケーリングを拡張した。
Ali, Y.*; 伊奈 拓也*; 小野寺 直幸; 井戸村 泰宏
no journal, ,
圧力ポアソン方程式のクリロフ部分空間法ソルバは大規模多相CFDシミュレーションにおいて全計算コストの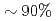 を占める。このポアソンソルバを加速するためにブロックヤコビ(BJ)前処理付きチェビシェフ基底共役勾配法(CBCG)ソルバをP100GPUに移植した。CBCGソルバはBJ前処理, 疎行列ベクトル積(SpMV), 非正方行列積から構成される。本研究ではスレッド・ブロック並列処理と効率的なコアレスドロードのためにBJ前処理を再設計し、非正方行列積にBatched GEMMを適用した。上記最適化により全ての主要カーネルでルーフラインに基づく理論性能のを達成し、CPUノードに比べて一桁以上のノード性能向上が得られた。
を占める。このポアソンソルバを加速するためにブロックヤコビ(BJ)前処理付きチェビシェフ基底共役勾配法(CBCG)ソルバをP100GPUに移植した。CBCGソルバはBJ前処理, 疎行列ベクトル積(SpMV), 非正方行列積から構成される。本研究ではスレッド・ブロック並列処理と効率的なコアレスドロードのためにBJ前処理を再設計し、非正方行列積にBatched GEMMを適用した。上記最適化により全ての主要カーネルでルーフラインに基づく理論性能のを達成し、CPUノードに比べて一桁以上のノード性能向上が得られた。
井戸村 泰宏; Ali, Y.*; 伊奈 拓也*; 今村 俊幸*
no journal, ,
クリロフ部分空間法に基づく差分陰解法はジャイロ運動論的トロイダル5次元オイラーコードGT5Dの主要な計算コストを占める。ポスト京重点課題では、演算加速に比べてノード間通信性能が限定的なエクサスケール計算機向けに先進的な省通信クリロフ部分空間法を開発してきた。本研究では、FP16前処理を用いた混合精度省通信GMRESソルバを開発する。この前処理により、反復回数と袖通信が大幅に削減された。新しいソルバを富岳とSUMMITに移植し、既存のマルチコア/メニーコアプロセッサにおける従来のソルバに対する性能比較を行う。
Ali, Y.*; 小野寺 直幸; 井戸村 泰宏; 伊奈 拓也*; 今村 俊幸*
no journal, ,
大規模原子力CFDシミュレーションにおいてクリロフソルバは全体計算コストのを占める。このようなCFDコードを加速するために、従来の前処理付共役残差(P-CG)法、および、前処理付チェビシェフ基底省通信共役残差(P-CBCG)法、省通信一般化最小残差(CA-GMRES)法という2種類の最新省通信アルゴリズムをGPUに移植した。本講演ではOpenACCとCUDAを用いた実装に対する性能移植性と性能向上のトレードオフを議論するとともに、最新のGPUスーパーコンピュータにおける性能テストを示す。
