


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Hasegawa, Yuta; Aoki, Takayuki*; Kobayashi, Hiromichi*; Idomura, Yasuhiro; Onodera, Naoyuki
Parallel Computing, 108, p.102851_1 - 102851_12, 2021/12
Times Cited Count:7 Percentile:50.25(Computer Science, Theory & Methods)The aerodynamics simulation code based on the lattice Boltzmann method (LBM) using forest-of-octrees-based block-structured local mesh refinement (LMR) was implemented, and its performance was evaluated on GPU-based supercomputers. We found that the conventional Space-Filling-Curve-based (SFC) domain partitioning algorithm results in costly halo communication in our aerodynamics simulations. Our new tree cutting approach improved the locality and the topology of the partitioned sub-domains and reduced the communication cost to one-third or one-fourth of the original SFC approach. In the strong scaling test, the code achieved maximum 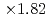 speedup at the performance of 2207 MLUPS (mega- lattice update per second) on 128 GPUs. In the weak scaling test, the code achieved 9620 MLUPS at 128 GPUs with 4.473 billion grid points, while the parallel efficiency was 93.4% from 8 to 128 GPUs.
speedup at the performance of 2207 MLUPS (mega- lattice update per second) on 128 GPUs. In the weak scaling test, the code achieved 9620 MLUPS at 128 GPUs with 4.473 billion grid points, while the parallel efficiency was 93.4% from 8 to 128 GPUs.
Hasegawa, Yuta; Aoki, Takayuki*; Kobayashi, Hiromichi*; Idomura, Yasuhiro; Onodera, Naoyuki
no journal, ,
We developed a block-structured static adaptive mesh refinement (AMR) CFD code for the aerodynamics simulation using the lattice Boltzmann method on GPU supercomputers. The data structure of AMR was based on the forest-of-octrees, and the domain partitioning algorithm was based on space-filling curves (SFCs). To reduce the halo data communication, we introduced the tree cutting approach, which divided the global domains with a few octrees into small sub-domains with many octrees, leading to a hierarchical domain partitioning approach with the coarse structured block and the fine SFC partitioning in each block. The tree cutting improved the locality of the sub-divided domain, and reduced both the amount of communication data and the number of connections of the halo communication. In the strong scaling test on the Tesla V100 GPU supercomputer, the tree cutting approach showed 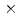 1.82 speedup at the performance of 2207 MLUPS (mega-lattice update per second) on 128 GPUs.
1.82 speedup at the performance of 2207 MLUPS (mega-lattice update per second) on 128 GPUs.
