


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Asahi, Yuichi; Padioleau, T.*; Latu, G.*; Bigot, J.*; Grandgirard, V.*; Obrejan, K.*
Dai-36-Kai Suchi Ryutai Rikigaku Shimpojiumu Koen Rombunshu (Internet), 8 Pages, 2022/12
We implement a kinetic plasma simulation code with multiple performance portable frameworks and evaluated its performance on Intel Icelake, NVIDIA V100 and A100 GPUs, and AMD MI100 GPU. Relying on the language standard parallelism stdpar and proposed language standard multi-dimensional array support mdspan, we demonstrate a performance portable implementation without harming the readability and productivity. With stdpar, we obtain a good overall performance for a kinetic plasma mini-application in the range of 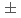 20% to the Kokkos version on Icelake, V100, A100 and MI100. We conclude that stdpar can be a good candidate to develop a performance portable and productive code targeting Exascale era platforms, assuming this programming model will be available on AMD and/or Intel GPUs in the future.
20% to the Kokkos version on Icelake, V100, A100 and MI100. We conclude that stdpar can be a good candidate to develop a performance portable and productive code targeting Exascale era platforms, assuming this programming model will be available on AMD and/or Intel GPUs in the future.
Asahi, Yuichi; Padioleau, T.*; Latu, G.*; Bigot, J.*; Grandgirard, V.*; Obrejan, K.*
Proceedings of 2022 International Workshop on Performance, Portability, and Productivity in HPC (P3HPC) (Internet), p.68 - 80, 2022/11
Times Cited Count:6 Percentile:75.01(Computer Science, Theory & Methods)This paper presents the performance portable implementation of a kinetic plasma simulation code with C++ parallel algorithm to run across multiple CPUs and GPUs. Relying on the language standard parallelism stdpar and proposed language standard multi-dimensional array support mdspan, we demonstrate that a performance portable implementation is possible without harming the readability and productivity. We obtain a good overall performance for a mini-application in the range of 20% to the Kokkos version on Intel Icelake, NVIDIA V100, and A100 GPUs. Our conclusion is that stdpar can be a good candidate to develop a performance portable and productive code targeting the Exascale era platform, assuming this approach will be available on AMD and/or Intel GPUs in the future.
Asahi, Yuichi; Latu, G.*; Bigot, J.*; Grandgirard, V.*
Proceedings of 2021 International Workshop on Performance, Portability, and Productivity in HPC (P3HPC) (Internet), p.79 - 91, 2021/11
This paper presents optimization strategies dedicated to a kinetic plasma simulation code that makes use of OpenACC/OpenMP directives and Kokkos performance portable framework to run across multiple CPUs and GPUs. We evaluate the impacts of optimizations on multiple hardware platforms: Intel Xeon Skylake, Fujitsu Arm A64FX, and Nvidia Tesla P100 and V100. After the optimizations, the OpenACC/OpenMP version achieved the acceleration of 1.07 to 1.39. The Kokkos version in turn achieved the acceleration of 1.00 to 1.33. Since the impact of optimizations under multiple combinations of kernels, devices and parallel implementations is demonstrated, this paper provides a widely available approach to accelerate a code keeping the performance portability. To achieve an excellent performance on both CPUs and GPUs, Kokkos could be a reasonable choice which offers more flexibility to manage multiple data and loop structures with a single codebase.
Asahi, Yuichi; Fujii, Keisuke*; Heim, D. M.*; Maeyama, Shinya*; Garbet, X.*; Grandgirard, V.*; Sarazin, Y.*; Dif-Pradalier, G.*; Idomura, Yasuhiro; Yagi, Masatoshi*
Physics of Plasmas, 28(1), p.012304_1 - 012304_21, 2021/01
Times Cited Count:6 Percentile:42.02(Physics, Fluids & Plasmas)This article demonstrates a data compression technique for the time series of five dimensional distribution function data based on Principal Component Analysis (PCA). Phase space bases and corresponding coefficients are constructed by PCA in order to reduce the data size and the dimensionality. It is shown that about 83% of the variance of the original five dimensional distribution can be expressed with 64 components. This leads to the compression of the degrees of freedom from 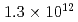 to
to 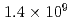 . One of the important findings - resulting from the detailed analysis of the contribution of each principal component to the energy flux - deals with avalanche events, which are found to be mostly driven by coherent structures in the phase space, indicating the key role of resonant particles.
. One of the important findings - resulting from the detailed analysis of the contribution of each principal component to the energy flux - deals with avalanche events, which are found to be mostly driven by coherent structures in the phase space, indicating the key role of resonant particles.
Asahi, Yuichi; Latu, G.*; Bigot, J.*; Grandgirard, V.*
Proceedings of Joint International Conference on Supercomputing in Nuclear Applications + Monte Carlo 2020 (SNA + MC 2020), p.218 - 224, 2020/10
Performance portability is expected to be a critical issue in the upcoming exascale era. We explore a performance portable approach for a fusion plasma turbulence simulation code employing the kinetic model, namely the GYSELA code. For this purpose, we extract the key features of GYSELA such as the high dimensionality (more than 4D) and the semi-Lagrangian scheme, and encapsulate them into a mini-application which solves the similar but a simplified Vlasov-Poisson system as GYSELA. We implement the mini-app with OpenACC, OpenMP4.5 and Kokkos, where we suppress unnecessary duplications of code lines. Based on our experience, we discuss the advantages and disadvantages of OpenACC, OpenMP4.5 and Kokkos, from the view point of performance portability, readability and productivity.
Asahi, Yuichi*; Latu, G.*; Bigot, J.*; Maeyama, Shinya*; Grandgirard, V.*; Idomura, Yasuhiro
Concurrency and Computation; Practice and Experience, 32(5), p.e5551_1 - e5551_21, 2020/03
Times Cited Count:1 Percentile:11.55(Computer Science, Software Engineering)Two five-dimensional gyrokinetic codes GYSELA and GKV were ported to the modern accelerators, Xeon Phi KNL and Tesla P100 GPU. Serial computing kernels of GYSELA on KNL and GKV on P100 GPU were respectively 1.3x and 7.4x faster than those on a single Skylake processor. Scaling tests of GYSELA and GKV were respectively performed from 16 to 512 KNLs and from 32 to 256 P100 GPUs, and data transpose communications in semi-Lagrangian kernels in GYSELA and in convolution kernels in GKV were found to be main bottlenecks, respectively. In order to mitigate the communication costs, pipeline-based and task-based communication overlapping were implemented in these codes.
Asahi, Yuichi*; Grandgirard, V.*; Sarazin, Y.*; Donnel, P.*; Garbet, X.*; Idomura, Yasuhiro; Dif-Pradalier, G.*; Latu, G.*
Plasma Physics and Controlled Fusion, 61(6), p.065015_1 - 065015_15, 2019/05
Times Cited Count:5 Percentile:27.41(Physics, Fluids & Plasmas)The role of poloidal convective cells on transport processes is studied with the full-F gyrokinetic code GYSELA. For this purpose, we apply a numerical filter to convective cells and compare the simulation results with and without the filter. The energy flux driven by the magnetic drifts turns out to be reduced by a factor of about 2 once the numerical filter is applied. A careful analysis reveals that the frequency spectrum of the convective cells is well-correlated with that of the turbulent Reynolds stress tensor, giving credit to their turbulence-driven origin. The impact of convective cells can be interpreted as a synergy between turbulence and neoclassical dynamics.
Asahi, Yuichi*; Grandgirard, V.*; Idomura, Yasuhiro; Garbet, X.*; Latu, G.*; Sarazin, Y.*; Dif-Pradalier, G.*; Donnel, P.*; Ehrlacher, C.*
Physics of Plasmas, 24(10), p.102515_1 - 102515_17, 2017/10
Times Cited Count:10 Percentile:44.32(Physics, Fluids & Plasmas)Two full-F global gyrokinetic codes are benchmarked to compute flux-driven ion temperature gradient turbulence in tokamak plasmas. For this purpose, the Semi-Lagrangian code GYSELA and the Eulerian code GT5D are employed, which solve the full-F gyrokinetic equation with a realistic fixed flux condition. Using the appropriate settings for the boundary and initial conditions, flux-driven ITG turbulence simulations are carried out. The avalanche-like transport is assessed with a focus on spatio-temporal properties. A statistical analysis is performed to discuss this self-organized criticality (SOC) like behaviors, where we found 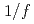 spectra and a transition to
spectra and a transition to 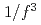 spectra at high-frequency side in both codes. Based on these benchmarks, it is verified that the SOC-like behavior is robust and not dependent on numerics.
spectra at high-frequency side in both codes. Based on these benchmarks, it is verified that the SOC-like behavior is robust and not dependent on numerics.
Asahi, Yuichi*; Latu, G.*; Ina, Takuya; Idomura, Yasuhiro; Grandgirard, V.*; Garbet, X.*
IEEE Transactions on Parallel and Distributed Systems, 28(7), p.1974 - 1988, 2017/07
Times Cited Count:8 Percentile:51.40(Computer Science, Theory & Methods)High-dimensional stencil computation from fusion plasma turbulence codes involving complex memory access patterns, the indirect memory access in a Semi-Lagrangian scheme and the strided memory access in a Finite-Difference scheme, are optimized on accelerators such as GPGPUs and Xeon Phi coprocessors. On both devices, the Array of Structure of Array (AoSoA) data layout is preferable for contiguous memory accesses. It is shown that the effective local cache usage by improving spatial and temporal data locality is critical on Xeon Phi. On GPGPU, the texture memory usage improves the performance of the indirect memory accesses in the Semi-Lagrangian scheme. Thanks to these optimizations, the fusion kernels on accelerators become 1.4x - 8.1x faster than those on Sandy Bridge (CPU).
Villard, L.*; Bottino, A.*; Brunner, S.*; Casati, A.*; Chowdhury, J.*; Dannert, T.*; Ganesh, R.*; Garbet, X.*; G rler, T.*; Grandgirard, V.*; et al.
rler, T.*; Grandgirard, V.*; et al.
Plasma Physics and Controlled Fusion, 52(12), p.124038_1 - 124038_18, 2010/11
Times Cited Count:21 Percentile:60.02(Physics, Fluids & Plasmas)Asahi, Yuichi*; Garbet, X.*; Idomura, Yasuhiro; Grandgirard, V.*; Latu, G.*; Sarazin, Y.*; Dif-Pradalier, G.*; Donnel, P.*; Ehrlacher, C.*; Passeron, Ch.*
no journal, ,
Two global full-f gyrokinetic codes, which have been developed at CEA and JAEA, are benchmarked. Quantitative agreements between two codes are obtained regarding linear processes such as the linear stability of ion temperature gradient driven modes, the linear damping of zonal flows, and the collisional transport. Preliminary benchmarks on nonlinear turbulence simulations show some differences of calculation results, which arise due to differences in calculation models such as boundary conditions and heat source models, and the remaining issues towards quantitative nonlinear benchmarks are clarified.
Asahi, Yuichi; Maeyama, Shinya*; Bigot, J.*; Garbet, X.*; Grandgirard, V.*; Obrejan, K.*; Padioleau, T.*; Fujii, Keisuke*; Shimokawabe, Takashi*; Watanabe, Tomohiko*; et al.
no journal, ,
We will demonstrate the performance portable implementation of a kinetic plasma code over CPUs, Nvidia and AMD GPUs. We will also discuss the performance portability of the code with C++ parallel algorithm. Deep learning based surrogate models for fluid simulations will also be demonstrated.
Asahi, Yuichi*; Latu, G.*; Ina, Takuya; Idomura, Yasuhiro; Grandgirard, V.*; Garbet, X.*
no journal, ,
Computation kernels of fusion plasma turbulence codes based on the Semi-Lagrangian scheme and the Finite-Difference scheme are optimized on latest many core processors such as GPGPU, XeonPhi, and FX100, and 1.4x-8.1x speedup is achieved. Affinity between different memory access patterns in each numerical scheme and difference memory-cache architectures on each hardware is studied, and different optimization techniques are developed for each architecture. On Xeon Phi, thread load balance is improved, and an optimization technique for effective local cache usage is developed. On GPGPU, an optimization technique using a texture memory and an implementation to reuse registers are developed. On the other hand, on FX100, it is found that the conventional optimization techniques for CPU work.
Asahi, Yuichi; Latu, G.*; Bigot, J.*; Grandgirard, V.*
no journal, ,
To prepare the performance portable version of the kinetic plasma simulation code, we develop a simplified but self-contained semi-Lagrangian mini-app with Kokkos performance portable framework and OpenMP/OpenACC which works on both CPUs and GPUs. We investigate the performance of the mini-app over the novel arm-based processor Fujitsu A64FX, Nvidia Tesla GPU, and Intel Skylake, where the arm-based architectures and GPUs are supposed to be major architectures in the exa-scale supercomputing era. The porting cost is highly suppressed with both Kokkos and directive implementations, where the code duplication is avoided. The higher performance portability is achieved with OpenMP/OpenACC, particularly for the compute intense kernels among the hotspots. Unfortunately, a relatively low performance is obtained on A64FX for kernels with indirect memory accesses. We also discuss what kind of Kokkos/OpenMP/OpenACC features are useful to improve the readability and productivity.
Asahi, Yuichi; Maeyama, Shinya*; Bigot, J.*; Garbet, X.*; Grandgirard, V.*; Fujii, Keisuke*; Shimokawabe, Takashi*; Watanabe, Tomohiko*; Idomura, Yasuhiro; Onodera, Naoyuki; et al.
no journal, ,
We have established an in-situ data analysis method for large scale fluid simulation data and developed deep learning based surrogate models to predict fluid simulation results. Firstly, we have developed an in-situ data processing approach, which loosely couples the MPI application and python scripts. It has been shown that this approach is simple and efficient which offers the speedup of 2.7 compared to post hoc data processing. Secondly, we have developed a deep learning model for predicting multiresolution steady flow fields. The deep learning model can give reasonably accurate predictions of simulation results with orders of magnitude faster compared to simulations.
Asahi, Yuichi; Latu, G.*; Ina, Takuya; Idomura, Yasuhiro; Grandgirard, V.*; Garbet, X.*
no journal, ,
We present the optimization of kernels from fusion plasma codes, GYSELA and GT5D, on Tera-flops many-core architectures including accelerators (Xeon Phi, GPU), and a multi-core CPU (FX100). GYSELA kernel is based on a semi-Lagrangian scheme with high arithmetic intensity. Through the optimization of GYSELA kernel on Xeon Phi, we show the importance of the vectorization of a code. For GT5D kernel, which is based on a finite difference scheme, a sophisticated memory access is necessary for attaining high performance. Through the optimization of GT5D kernel on GPUs, we show the effective optimization for memory access with the help of the shared memory.
Asahi, Yuichi; Idomura, Yasuhiro; Ina, Takuya; Garbet, X.*; Grandgirard, V.*; Latu, G.*
no journal, ,
In the so-called delta-f gyrokinetic simulations, the scale separation between the equilibrium and fluctuation plasmas is assumed, and the time evolution is solved only for the fluctuation part. In contrast, in the full-f gyrokinetic simulations, both of the equilibrium and fluctuation plasmas are solved on the basis of the same first principle, where the self-consistent simulations for the equilibrium and fluctuation plasmas are possible. So far, there are a plenty number of cross-code benchmarks for delta-f gyrokinetic simulations, which helps to improve the robustness of the simulations. However, this is not the case for the full-f simulations since the complicated full-f physics makes benchmarks more difficult. In the presentation, we will show the progress of the full-f benchmarks and discuss the confronting issues.
Grandgirard, V.*; Asahi, Yuichi; Bigot, J.*; Bourne, E.*; Dif-Pradalier, G.*; Donnel, P.*; Garbet, X.*; Ghendrih, P.*
no journal, ,
Core transport modelling in tokamak plasmas has now reached maturity with non-linear 5D gyrokinetic codes in the world available to address this issue. However, despite numerous successes, their predictive capabilities are still challenged, especially for optimized discharges. Bridging this gap requires extending gyrokinetic modelling in the edge and close to the material boundaries, preferably addressing edge and core transport on an equal footing. This is one of the long term challenges for the petascale code GYSELA [V. Grandgirard et al., CPC 2017 (35)]. Edge-core turbulent plasma simulations with kinetic electrons will require exascale HPC capabilities. We present here the different strategies that we are currently exploring to target the disruptive use of billions of computing cores expected in exascale-class supercomputer as OpenMP4.5 tasks for overlapping computations and MPI communications, KOKKOS for performant portability programming and code refactoring.
Asahi, Yuichi; Maeyama, Shinya*; Bigot, J.*; Garbet, X.*; Grandgirard, V.*; Obrejan, K.*; Padioleau, T.*; Fujii, Keisuke*; Shimokawabe, Takashi*; Watanabe, Tomohiko*; et al.
no journal, ,
We will demonstrate the performance portable implementation of a kinetic plasma code over CPUs, Nvidia and AMD GPUs. We will also discuss the performance portability of the code with C++ parallel algorithm. Deep learning based surrogate models for fluid simulations will also be demonstrated.
Asahi, Yuichi; Hasegawa, Yuta; Padioleau, T.*; Millan, A.*; Bigot, J.*; Grandgirard, V.*; Obrejan, K.*
no journal, ,
Generally, production-ready scientific simulations consist of many different tasks including computations, communications and file I/O. Compared to the accelerated computations with GPUs, communications and file I/O would be slower which can be major bottlenecks. It is thus quite important to manage these tasks concurrently to suppress these costs. In the present talk, we employ the proposed language standard C++ senders/receivers to mask the costs of communications and file I/O. As a case study, we implement a 2D turbulence simulation code with the local ensemble transform Kalman filter (LETKF) using C++ senders/receivers. In LETKF, the mock observation data are read from files followed by MPI communications and dense matrix operations on GPUs. We demonstrate the performance portable implementation with this framework, while exploiting the performance gain with the introduced concurrency.
Asahi, Yuichi*; Grandgirard, V.*; Idomura, Yasuhiro; Sarazin, Y.*; Latu, G.*; Garbet, X.*
no journal, ,
This talk reviews outcomes from BMTFF projects, which was conducted for FY2015-2016. In this project, in order to establish a firm basis of full-f gyrokinetic models, two major full-f gyrokinetic codes in EU and Japan, GYSELA and GT5D, were benchmarked. In FY2015, all the numerical implementations were examined, and boundary conditions were fixed to be the same. With this correction, collisional transport, linear zonal flow damping, and linear stability of the ion temperature gradient driven (ITG) mode were successfully benchmarked. In FY2016, the same source and sink models were implemented in both codes, and nonlinear turbulence simulations were benchmarked. Decaying ITG turbulence simulations without heat sources showed similar profile relaxation processes, and nonlinear critical temperature gradients agreed quantitatively with each other. On the other hand, driven ITG turbulence simulations with heat sources showed intermittent bursts of avalanche like transport, which indicate similar 1/f type frequency spectra.

