


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Yoshida, M.*; McDermott, R. M.*; Angioni, C.*; Camenen, Y.*; Citrin, J.*; Jakubowski, M.*; Hughes, J. W.*; Idomura, Yasuhiro; Mantica, P.*; Mariani, A.*; et al.
Nuclear Fusion, 65(3), p.033001_1 - 033001_132, 2025/02
Times Cited Count:4 Percentile:95.90(Physics, Fluids & Plasmas)Progress in physics understanding and theoretical model development of plasma transport and confinement in the ITPA Transport and Confinement Topical Group since the publication of the ITER Physics Basis was summarized focusing on the contributions to ITER and burning plasma prediction and control. This paper provides a general and streamlined overview on the advances that were mainly led by the ITPA TC joint experiments and joint activities for the last 15 years. This paper starts with the scientific strategy and scope of the ITPA TC Topical group and overall picture of the major progress, followed by the progress of each research field: particle transport, impurity transport, ion and electron thermal turbulent transport, momentum transport, impact of 3D magnetic fields on transport, confinement mode transitions, global confinement, and reduced transport modeling.
Kawamura, Takuma; Shimomura, Kazuya; Osaki, Tsukasa*; Idomura, Yasuhiro
EPJ Web of Conferences, 302, p.11002_1 - 11002_8, 2024/10
Times Cited Count:0 Percentile:0.00(Computer Science, Interdisciplinary Applications)In the field of nuclear engineering, complex simulations on exa-scale supercomputers generate large-scale data. To facilitate efficient analysis of such simulation data, one needs to share them among scientists at remote locations. However, data I/O and data transfer for such large-scale data are quite costly. To resolve these issues, we developed a remote in-situ visualization system IS-PBVR based on the particle-based volume rendering (PBVR), which is suitable for parallel processing on modern supercomputers. In this study, we extend IS-PBVR for VR visualization on multiple client PCs, thus developing a multi-point remote VR visualization. We apply this technique to fluid simulations on GPU-based supercomputers and verify its utility by sharing in-situ VR visualization between multiple client PCs.
Sugihara, Kenta; Onodera, Naoyuki; Sitompul, Y.; Idomura, Yasuhiro; Yamashita, Susumu
EPJ Web of Conferences, 302, p.03002_1 - 03002_10, 2024/10
Times Cited Count:1 Percentile:0.00(Computer Science, Interdisciplinary Applications)In simulations of gas-liquid two-phase flows using conventional interface capture methods, we observed that when bubbles come close to each other, they tend to merge numerically, despite experimental evidence indicating that they would repel each other. Given the significant impact of sequential numerical coalescence on flow patterns, it is necessary to regulate the merging behavior of close bubbles. To address this issue, we introduced the Multi- Phase Field (MPF) method, which mitigates bubble coalescence by applying an independent fluid fraction function to each bubble. In this study, we employed the MPF based on the N-phase model to minimize numerical errors associated with surface interactions at triple junction points. Additionally, we implemented the Ordered Active Parameter Tracking (OAPT) method to efficiently store several hundreds of fluid fraction functions. To validate the MPF method, we conducted analysis of turbulent bubbly pipe flows and compared the results against experimental data from Colin et al. The validation results showed reasonable agreements with respect to the bubble distribution and the flow velocity profiles.
Hasegawa, Yuta; Idomura, Yasuhiro; Onodera, Naoyuki
EPJ Web of Conferences, 302, p.03005_1 - 03005_9, 2024/10
Times Cited Count:0 Percentile:0.00(Computer Science, Interdisciplinary Applications)We implemented the ensemble data assimilation (DA) method, the local ensemble transform Kalman filter (LETKF), into the mesh-refined lattice Boltzmann method (LBM) for turbulent flows. Both the LETKF and the mesh-refined LBM were fully implemented on GPUs, so that they are efficiently computed on modern GPU-based supercomputers. We examined the DA accuracy against the flow around a cylinder. The result showed that our method enabled accurate DA with spatially- and temporarily-sparse observation data; the error of the assimilated velocity field with the observation interval of 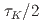 and the observation resolution
and the observation resolution 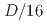 (1.56% of the total computational grids) was smaller than the amplitude of the observation noise, where
(1.56% of the total computational grids) was smaller than the amplitude of the observation noise, where 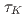 is the period of the K
is the period of the K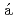 rmn vortex and
rmn vortex and 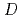 is diameter of the square cylinder.
is diameter of the square cylinder.
Sitompul, Y.; Sugihara, Kenta; Onodera, Naoyuki; Idomura, Yasuhiro
EPJ Web of Conferences, 302, p.05004_1 - 05004_10, 2024/10
Times Cited Count:1 Percentile:94.62(Computer Science, Interdisciplinary Applications)In fast reactor designs, it is of critical importance to avoid gas entrainment phenomena due to free-surface vortices. Numerical analysis is one of the key methods to understand these phenomena. However, the challenges in computational efficiency and accuracy of the previous numerical methods lead to exploring the Lattice Boltzmann method (LBM) as an alternative, known for its computational efficiency and capability in simulating complex flows. In this study, we implement free-surface LBM to accelerate gas entrainment analysis, significantly reducing computational costs while maintaining accuracy compared to traditional methods. Simulation results using LBM align well with experimental data, offering a promising avenue for faster analysis in future fast reactor designs.
Idomura, Yasuhiro
Physics of Plasmas, 31(10), p.102504_1 - 102504_10, 2024/10
Times Cited Count:0 Percentile:0.00(Physics, Fluids & Plasmas)Hydrogen isotope mixing phenomena in tokamak plasmas are analyzed using global full-f gyrokinetic simulations. Model plasma parameters are chosen based on the hydrogen isotope pellet experiments on JET, in which hydrogen isotope mixing in the time scale of the energy confinement time occurred after injecting deuterium (D) pellets into hydrogen (H) plasmas. Two numerical experiments are conducted using plasma profiles before and after the D pellet injection. In both cases, turbulent fluctuations in the plasma core are characterized by ion temperature gradient driven turbulence, while in the latter case, trapped electron mode turbulence also exists in the outer region. In the former case, the density profile of bulk H ions is kept in a quasi-steady state, and the particle confinement time of bulk H ions is an order of magnitude longer than the energy confinement time. In the latter case, the density profiles of bulk H ions and pellet D ions show transient relaxation in the time scale of the energy confinement time, indicating the fast hydrogen isotope mixing. In the toroidal angular momentum balance, it is found that the hydrogen isotope mixing is driven by the toroidal field stress.
Hasegawa, Yuta; Idomura, Yasuhiro; Onodera, Naoyuki
Keisan Kogaku Koenkai Rombunshu (CD-ROM), 29, 4 Pages, 2024/06
We implemented the ensemble data assimilation (DA) of turbulence by using the mesh-refined lattice Boltzmann method with the local ensemble transform Kalman filter (LBM-LETKF). We examined the accuracy of the data assimilation against a turbulent flow around a three-dimensional square cylinder. The DA error was comparable or less than the observation noise when the observation interval was a half of the period of the Krmn vortex street and the number of observation points was 0.195% of computational grid points. The LBM-LETKF enables DA of turbulence with spatially- and temporally- sparse observations.
Onodera, Naoyuki; Sugihara, Kenta; Ina, Takuya; Idomura, Yasuhiro
Keisan Kogaku Koenkai Rombunshu (CD-ROM), 29, 3 Pages, 2024/06
Gas-liquid two-phase flow analysis is one of the most important research topics in nuclear engineering because it is essential for safety evaluation and reactor design. However, it requires large-scale multi-scale simulations, and advanced numerical approaches are needed. To meet this challenge, we have continued to develop the Poisson solver for the multiphase flow analysis code JUPITER. In this study, we aim to improve the convergence of the pressure Poisson solver by formulating the Navier-Stokes equation without using the incompressible approximation. The convergence performance was measured on 8 GPUs for bubbly flow analysis in a circular tube. The results show that the computation time and the number of iterations are reduced by half compared to those using the incompressible approximation, which indicates the usefulness of the formulation in the present study.
Kawamura, Takuma; Hasegawa, Yuta; Idomura, Yasuhiro
Journal of Visualization, 27(1), p.89 - 107, 2024/02
Times Cited Count:2 Percentile:27.40(Computer Science, Interdisciplinary Applications)Interactive in-situ steering is an effective tool for debugging, searching for optimal solutions, and analyzing inverse problems in fast and large-scale computational fluid dynamics (CFD) simulations. We propose an interactive in-situ steering framework for large-scale CFD simulations on GPU supercomputers. This framework employs in-situ particle-based volume rendering (PBVR), in-situ data sampling, and a file-based control that enables interactive communication of steering parameters, compressed particle data, and sampled monitoring data between supercomputers and user PCs. The parallelized PBVR is processed on the host CPU to avoid interference with CFD simulations on the GPU. We apply the proposed framework to a real-time plume dispersion analysis code CityLBM on GPU supercomputers. In the numerical experiment, we address an inverse problem to find a pollutant source from the monitoring data, and demonstrate the effectiveness of the human-in-the-loop approach.
Hasegawa, Yuta; Onodera, Naoyuki; Asahi, Yuichi; Ina, Takuya; Imamura, Toshiyuki*; Idomura, Yasuhiro
Fluid Dynamics Research, 55(6), p.065501_1 - 065501_25, 2023/11
Times Cited Count:1 Percentile:13.13(Mechanics)We investigate the applicability of the data assimilation (DA) to large eddy simulations (LESs) based on the lattice Boltzmann method (LBM). We carry out the observing system simulation experiment of a two-dimensional (2D) forced isotropic turbulence, and examine the DA accuracy of the nudging and the local ensemble transform Kalman filter (LETKF) with spatially sparse and noisy observation data of flow fields. The advantage of the LETKF is that it does not require computing spatial interpolation and/or an inverse problem between the macroscopic variables (the density and the pressure) and the velocity distribution function of the LBM, while the nudging introduces additional models for them. The numerical experiments with 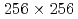 grids and 10% observation noise in the velocity showed that the root mean square error of the velocity in the LETKF with
grids and 10% observation noise in the velocity showed that the root mean square error of the velocity in the LETKF with 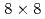 observation points (
observation points (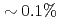 of the total grids) and 64 ensemble members becomes smaller than the observation noise, while the nudging requires an order of magnitude larger number of observation points to achieve the same accuracy. Another advantage of the LETKF is that it well keeps the amplitude of the energy spectrum, while only the phase error becomes larger with more sparse observation. From these results, it was shown that the LETKF enables robust and accurate DA for the 2D LBM with sparse and noisy observation data.
of the total grids) and 64 ensemble members becomes smaller than the observation noise, while the nudging requires an order of magnitude larger number of observation points to achieve the same accuracy. Another advantage of the LETKF is that it well keeps the amplitude of the energy spectrum, while only the phase error becomes larger with more sparse observation. From these results, it was shown that the LETKF enables robust and accurate DA for the 2D LBM with sparse and noisy observation data.
Sugihara, Kenta; Onodera, Naoyuki; Idomura, Yasuhiro; Yamashita, Susumu
JAEA-Research 2023-006, 47 Pages, 2023/10
 JAEA-Research-2023-006.pdf:3.28MB
JAEA-Research-2023-006.pdf:3.28MB
This report presents a new surface capturing method based on the phase field model for gas-liquid two-phase flows simulation. In the conventional phase field model, the interface correction strength parameter was determined from the maximum flow velocity in the computational domain, but because the interface correction was applied uniformly to the entire space, it was also applied to locations that did not require correction. In the new method, the phase field parameter or the intensity of the phase field model is extended to have a spatial distribution, allowing us to set the optimal parameters depending on the local flow velocity fields. We also propose a method to derive the optimal phase field parameter based on systematic parameter scans using error analysis of the interface advection test and bubble rising calculations. Through benchmark tests of gas-liquid two-phase flows, the proposed model is verified, and it is shown that the proposed model has higher accuracy than the conventional phase field model.
Hasegawa, Yuta; Onodera, Naoyuki; Asahi, Yuichi; Idomura, Yasuhiro
Keisan Kogaku Koenkai Rombunshu (CD-ROM), 28, 5 Pages, 2023/05
We implemented and investigated the data assimilation (DA) of two-dimensional isotropic turbulence using the lattice Boltzmann method and the local ensemble transform Kalman filter (LBM-LETKF). We carried out the numerical experiment with 256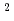 grids, 256 or less observation points, 10% root mean square (RMS) observation noise in the velocity observation, and 4, 16, or 64 ensemble members. The numerical experiment showed that the accuracy of the LETKF was better than the nudging DA with both dense and sparse observation. The lack of observation points caused the numerical instability in the LETKF, but such a numerical instability can be suppressed by increasing the number of ensemble members. In the sparse observation case (8
grids, 256 or less observation points, 10% root mean square (RMS) observation noise in the velocity observation, and 4, 16, or 64 ensemble members. The numerical experiment showed that the accuracy of the LETKF was better than the nudging DA with both dense and sparse observation. The lack of observation points caused the numerical instability in the LETKF, but such a numerical instability can be suppressed by increasing the number of ensemble members. In the sparse observation case (8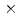 8 observation points) with 64 ensemble members, the root means squared error (RMSE) of the velocity in the LBM-LETKF was smaller than the RMS of the observation noise, while the nudging DA required 3232 observation points to obtain the same accuracy. Overall, the LETKF with sufficiently large number of ensemble members was highly accurate and robust, thus, the LETKF was a good choice for the DA of turbulent flows using the LBM.
8 observation points) with 64 ensemble members, the root means squared error (RMSE) of the velocity in the LBM-LETKF was smaller than the RMS of the observation noise, while the nudging DA required 3232 observation points to obtain the same accuracy. Overall, the LETKF with sufficiently large number of ensemble members was highly accurate and robust, thus, the LETKF was a good choice for the DA of turbulent flows using the LBM.
Onodera, Naoyuki; Idomura, Yasuhiro; Hasegawa, Yuta; Asahi, Yuichi; Inagaki, Atsushi*; Shimose, Kenichi*; Hirano, Kohin*
Keisan Kogaku Koenkai Rombunshu (CD-ROM), 28, 4 Pages, 2023/05
We have developed a multi-scale wind simulation code named CityLBM that can resolve entire cities to detailed streets. CityLBM enables a real time ensemble simulation for several km square area by applying the locally mesh-refined lattice Boltzmann method on GPU supercomputers. On the other hand, real-world wind simulations contain complex boundary conditions that cannot be modeled, so data assimilation techniques are needed to reflect observed data in the simulation. This study proposes an optimization method for ground surface temperature bias based on an ensemble Kalman filter to reproduce wind conditions within urban city blocks. As a verification of CityLBM, an Observing System Simulation Experiment (OSSE) is conducted for the central Tokyo area to estimate boundary conditions from observed near-surface temperature values.
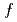 gyrokinetic simulations of ohmic L-mode plasmas in linear and saturated ohmic confinement regimes
gyrokinetic simulations of ohmic L-mode plasmas in linear and saturated ohmic confinement regimesIdomura, Yasuhiro; Dif-Pradalier, G.*; Garbet, X.*; Sarazin, Y.*; Tore Supra Teams*
Physics of Plasmas, 30(4), p.042508_1 - 042508_18, 2023/04
Times Cited Count:2 Percentile:27.59(Physics, Fluids & Plasmas)Two time slices in linear and saturated ohmic confinement (LOC and SOC) regimes in a Tore Supra ohmic L-mode discharge are analyzed using nonlinear global full- gyrokinetic simulations, and qualitative features of the LOC-SOC transition are reproduced. The exhaust of carbon impurity ions is caused by fast ion mixing, which is driven by the toroidal field stress. The intrinsic rotation develops in the opposite direction between the LOC and SOC phases, which is characterized by the different features of the mode asymmetry between trapped electron modes in the LOC phase and ion temperature gradient driven modes in the SOC phase, leading to the change of the profile shear stress. The energy fluxes of electrons and deuterium ions are dominant in the LOC and SOC phases, respectively, and the ratio of the energy confinement time between two phases agree with the experimental value.
Asahi, Yuichi; Onodera, Naoyuki; Hasegawa, Yuta; Shimokawabe, Takashi*; Shiba, Hayato*; Idomura, Yasuhiro
Boundary-Layer Meteorology, 186(3), p.659 - 692, 2023/03
Times Cited Count:2 Percentile:25.47(Meteorology & Atmospheric Sciences)We develop a Transformer-based deep learning model to predict the plume concentrations in the urban area under uniform flow conditions. Our model has two distinct input layers: Transformer layers for sequential data and convolutional layers in convolutional neural networks (CNNs) for image-like data. Our model can predict the plume concentration from realistically available data such as the time series monitoring data at a few observation stations and the building shapes and the source location. It is shown that the model can give reasonably accurate prediction with orders of magnitude faster than CFD simulations. It is also shown that the exactly same model can be applied to predict the source location, which also gives reasonable prediction accuracy.
Ina, Takuya; Idomura, Yasuhiro; Imamura, Toshiyuki*; Onodera, Naoyuki
Proceedings of International Conference on High Performance Computing in Asia-Pacific Region (HPC Asia 2023) (Internet), p.29 - 34, 2023/02
Mixed precision Krylov solvers with the Jacobi preconditioner often show significant convergence degradation when the Jacobi preconditioner is computed in low precision such as FP16 and BF16. It is found that this convergence degradation is attributed to loss of diagonal dominance due to roundoff errors in data conversion. To resolve this issue, we propose a new data conversion method, which is designed to keep diagonal dominance of the original matrix data. The proposed method is tested by computing the Poisson equation using the conjugate gradient method, the general minimum residual method, and the biconjugate gradient stabilized method with the FP16/BF16 Jacobi preconditioner on NVIDIA V100 GPUs. Here, the new data conversion is implemented by switching the round-nearest, round-up, round-down, and round-towards-zero intrinsics in CUDA, and is called once before the main iteration. Therefore, the cost of the new data conversion is negligible. When the coefficients of matrix is continuously changed by scaling the linear system, the conventional data conversion based on the round-nearest intrinsic shows periodic changes of the convergence property depending on the difference of the roundoff errors between diagonal and off-diagonal coefficients. Here, the period and magnitude of the convergence degradation depend on the bit length of significand. On the other hand, the proposed data conversion method is shown to fully avoid the convergence degradation, and robust mixed precision computing is enabled for the Jacobi preconditioner without extra overheads.
Onodera, Naoyuki; Idomura, Yasuhiro; Hasegawa, Yuta; Nakayama, Hiromasa
Dai-36-Kai Suchi Ryutai Rikigaku Shimpojiumu Koen Rombunshu (Internet), 3 Pages, 2022/12
We have developed a wind simulation code named CityLBM to realize wind digital twins. Mesoscale wind conditions are given as boundary conditions in CityLBM by using a nudging data assimilation method. It is found that conventional approaches with constant nudging coefficients fail to reproduce turbulent intensity in long time simulations, where atmospheric stability conditions change significantly. We propose a dynamic parameter optimization method for the nudging coefficient based on an ensemble Kalman filter. CityLBM was validated against plume dispersion experiments in the complex urban environment of Oklahoma City. The nudging coefficient was updated to reduce the error of the turbulent intensity between the simulation and the observation. The mean error of velocity variance is reduced by 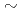 10% compared to the conventional nudging method with a constant nudging coefficient.
10% compared to the conventional nudging method with a constant nudging coefficient.
Hasegawa, Yuta; Onodera, Naoyuki; Asahi, Yuichi; Idomura, Yasuhiro
Dai-36-Kai Suchi Ryutai Rikigaku Shimpojiumu Koen Rombunshu (Internet), 5 Pages, 2022/12
This study implemented and tested the ensemble data assimilation (DA) of turbulent flows using the lattice Boltzmann method and the local ensemble transform Kalman filter (LBM-LETKF). The computational code was implemented fully on GPUs. The test was carried out for the 3D turbulent flow around a square cylinder with 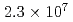 meshes and 32 ensemble members using 32 GPUs. The time interval of the DA in the test was a half of the period of the Kalman vortex shedding. The normalized mean absolute errors (NMAE) of the lift coefficient were 132%, 148%, and 13.2% for the non-DA case, the nudging case (a simpler DA algorithm), and the LETKF case, respectively. It was found that the LETKF achieved good DA accuracy even though the observation was not frequent enough for the small scale turbulence, while the nudging showed systematic delays in its solution, and could not keep the DA accurately.
meshes and 32 ensemble members using 32 GPUs. The time interval of the DA in the test was a half of the period of the Kalman vortex shedding. The normalized mean absolute errors (NMAE) of the lift coefficient were 132%, 148%, and 13.2% for the non-DA case, the nudging case (a simpler DA algorithm), and the LETKF case, respectively. It was found that the LETKF achieved good DA accuracy even though the observation was not frequent enough for the small scale turbulence, while the nudging showed systematic delays in its solution, and could not keep the DA accurately.
Sugihara, Kenta; Onodera, Naoyuki; Idomura, Yasuhiro; Yamashita, Susumu
Dai-36-Kai Suchi Ryutai Rikigaku Shimpojiumu Koen Rombunshu (Internet), 5 Pages, 2022/12
The conventional Allen-Cahn type multi-phase field method was modified to conserve not only the sum of the masses of all phases but also the mass of each phase. The interface advection calculations within a two-dimensional rotational velocity field were performed as a verification problem, and the conservation was successfully achieved. The proposed method was used to calculate the horizontally aligned pair of bubbles rising, and it was found that the bouncing phenomenon between bubbles can be calculated at 1/50 resolution of the high-resolution calculation by Zhang et al. using the volume of fluid method.
Nakayama, Hiromasa; Onodera, Naoyuki; Satoh, Daiki; Nagai, Haruyasu; Hasegawa, Yuta; Idomura, Yasuhiro
Journal of Nuclear Science and Technology, 59(10), p.1314 - 1329, 2022/10
Times Cited Count:5 Percentile:60.29(Nuclear Science & Technology)We developed a local-scale high-resolution atmospheric dispersion and dose assessment system (LHADDAS) for safety and consequence assessment of nuclear facilities and emergency response to nuclear accidents or deliberate releases of radioactive materials in built-up urban areas. This system is composed of pre-processing of input files, main calculation by local-scale high-resolution atmospheric dispersion model using large-eddy simulation (LOHDIM-LES) and real-time urban dispersion simulation model based on a lattice Boltzmann method (CityLBM), and post-processing of dose-calculation by simulation code powered by lattice dose-response functions (SIBYL). LHADDAS has a broad utility and offers superior performance in (1) simulating turbulent flows, plume dispersion, and dry deposition under realistic meteorological conditions, (2) performing real-time tracer dispersion simulations using a locally mesh-refined lattice Boltzmann method, and (3) estimating air dose rates of radionuclides from air concentrations and surface deposition in consideration of the influence of individual buildings and structures. This system is promising for safety assessment of nuclear facilities as an alternative to wind tunnel experiments, detailed pre/post-analyses of a local-scale radioactive plume dispersion in case of nuclear accidents, and quick response to emergency situations resulting from deliberate release of radioactive materials by a terrorist attack in an urban central district area.
