


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
徳久 淳師*; 新井 淳也*; 城地 保昌*; 大野 善之*; 亀山 豊久*; 山本 啓二*; 畑中 正行*; Gerofi, B.*; 島田 明男*; 黒川 原佳*; et al.
Journal of Synchrotron Radiation, 20(6), p.899 - 904, 2013/11
被引用回数:5 パーセンタイル:27.82(Instruments & Instrumentation)Single-particle coherent X-ray diffraction imaging using X-ray free electron laser has potential to reveal a three-dimensional structure of a biological supra-molecule at sub-nano meter resolution. In order to realize this method, it is necessary to analyze as many as one million noisy X-ray diffraction patterns, each for an unknown random target orientation. To cope with the severe quantum noise we need to classify patterns according to their similarities and average similar patterns to improve the S/N ratio. We developed a high-speed scalable scheme to carry out classification on the K computer, a 10PFLOPS supercomputer at RIKEN Advanced Institute for Computational Science. It is designed to work on the real time basis with the experimental diffraction pattern collection at the X-ray free electron laser facility SACLA so that the result of classification can be feed-backed to optimize experimental parameters during the experiment. We report the present status of our effort of developing the system and also a result of application to a set of simulated diffraction patterns. We succeeded in classification of about one million diffraction patterns by running 255 separate one-hour jobs on 385-node mode.
横川 三津夫; 斎藤 実*; 石原 卓*; 金田 行雄*
ハイパフォーマンスコンピューティングと計算科学シンポジウム(HPCS2002)論文集, p.125 - 131, 2002/01
近年のスーパーコンピュータの発展により、ナビエ・ストークス(NS)方程式の大規模な直接数値シミュレーション(DNS)が可能となってきた。しかし、乱流現象の解明とそのモデル化のためには、さらに大規模なDNSを行う必要がある。ピーク性能40Tflop/sの分散メモリ型並列計算機である地球シミュレータを用いて、大規模なDNSを行うためのスペクトル法を用いたDNSコード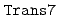 を開発し、既存コードとの比較により本コードの妥当性を検証した。格子点
を開発し、既存コードとの比較により本コードの妥当性を検証した。格子点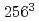 ,1APでの逐次版の実効性能は約3.72Gflop/sが得られた。また、並列版の実効効率は、単体ノードにおいてプロセッサ数にほぼ比例し、AP8台で7倍近い速度向上が得られた。8台のマルチノード環境では、ノード数の増加に伴い速度向上率が低下するが、格子点数
,1APでの逐次版の実効性能は約3.72Gflop/sが得られた。また、並列版の実効効率は、単体ノードにおいてプロセッサ数にほぼ比例し、AP8台で7倍近い速度向上が得られた。8台のマルチノード環境では、ノード数の増加に伴い速度向上率が低下するが、格子点数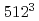 に対しピーク性能の25%の実効性能が得られた。
に対しピーク性能の25%の実効性能が得られた。
上原 均; 田村 正典; 横川 三津夫
ハイパフォーマンスコンピューティングと計算科学シンポジウム(HPCS2002)論文集, p.73 - 80, 2002/01
大気大循環シミュレーションなどの地球変動研究のための超大規模科学技術計算向けプラットフォームとして、地球シミュレータが現在開発されている。分散メモリ型並列計算機である地球シミュレータ上でプログラムを効率的に実行するには、プログラム内部での通信処理の効率化が必要で、そのためにも事前の通信性能評価は不可欠である。地球シミュレータでは通信用ライブラリとしてMPIが提供されることから、MPIの通信性能を詳細かつ多角的に計測するMBL1/MBL2を用いて、地球シミュレータの計算ノード上におけるMPIの性能計測と評価を行った。
横川 三津夫; 斎藤 実*; 萩原 孝*; 磯部 洋子*; 神宮寺 聡*
日本計算工学会論文集, 4, p.31 - 36, 2002/00
地球シミュレータは、640台の計算ノードをクロスバスイッチで結合した分散主記憶型並列計算機である。計算オードは8つのベクトルプロセッサからなる共有メモリシステムである。ピーク性能は40Tflops,主記憶容量は10TBである。地球シミュレータ上のプログラムの実効性能を推定するための性能予測システムGS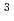 を開発した。GSのベクトル性能の予測精度を確認するために、3グループのカーネルループに対し、GSによる予測値とSX-4の測定値を比較した結果、実行時間の絶対誤差で0.89%,1.42%,6.81%が得られた。地球シミュレータの実効性能を予測した結果、 それぞれのグループで平均5.94Gflops,3.76Gflops,2.17Gflopsが得られた。
を開発した。GSのベクトル性能の予測精度を確認するために、3グループのカーネルループに対し、GSによる予測値とSX-4の測定値を比較した結果、実行時間の絶対誤差で0.89%,1.42%,6.81%が得られた。地球シミュレータの実効性能を予測した結果、 それぞれのグループで平均5.94Gflops,3.76Gflops,2.17Gflopsが得られた。
板倉 憲一; 横川 三津夫; 清水 大志; 君塚 肇*; 蕪木 英雄
情報処理学会研究報告2001-HPC-88, p.67 - 72, 2001/10
地球シミュレータは、640の計算ノードを持ち理論ピーク性能は40Tflop/sである。プロセッサノードはピーク性能8Gflop/sのベクトルプロセッサ8個,16GBの共有メモリから構成される。本研究では地球シミュレータの計算ノードによる固体分子動力学法の計算プログラムのベクトル化と並列化を行い性能評価を行った。分子動力学法では、カットオフ半径内の粒子が互いに影響を与え、その粒子ペアを行列を用いて表現することができる。ベクトル化に際して、この行列表現にcompressed row formとjagged diagonalformを考える。jagged diagonal formはベクトル長がcompressedrow formよりも長くできるので、ベクトル化により適している。しかし、標準的な粒子対の情報からjagged diagonal formに変換するには時間がかかるため、全体の性能はより簡単なcompressedrow fromよりも低下した。compressed row formでは8CPUでの並列化により2.4から2.7倍のスピードアップとなった。
上原 均; 津田 義典*; 横川 三津夫
情報処理学会研究報告2001-HPC-87, 2001(77), p.67 - 72, 2001/07
代表的なメッセージ通信APIであるMPIには、基本仕様としてのMPI-1と、拡張仕様としてのMPI-2がある。MPI-1で定義される関数のベンチマークは幾つか提案されているものの、MPI-2で定義される関数のベンチマークプログラムは少なく、その計測項目も限られている。そこでわれわれはMPI-2の、特に並列I/O(MPI-I/O)と片側通信(RMA)の性能を詳細に測定する MPI Benchmark program Library for MPI-2(MBL2)を構築した。本稿ではMBL2概要と幾つかの計算機のMPI-2性能データを報告する。
上原 均; 津田 義典*; 横川 三津夫
並列処理シンポジウム(JSPP2001)論文集, 2001(6), p.91 - 92, 2001/06
代表的なメッセージ通信APIであるMPIには、基本仕様のMPI-1と拡張仕様のMPI-2がある。MPI-1向けのベンチマークは幾つか提案されているが、MPI-2向けのベンチマークは少なく計測項目も限られている。そこでMPI-2(特に並列I/O(MPI-I/O)と片側通信(RMA))のベンチマーク(MBL2: MPI Benchmark program Library for MPI-2)の構築を試みた。
横川 三津夫
日本応用数理学会論文誌, 11(1), p.79 - 81, 2001/03
地球シミュレータシステムは、広い意味で地球シミュレータのハードウェア,オペレーティングシステムなどの基本ソフトウェア,及び地球シミュレータ上の応用ソフトウェアから構成される数値シミュレーションのための統合システムと云える。これは。科学技術庁が推進する地球環境変動予測研究の一環として開発されているものであり、特に地球シミュレータのハードウェアはこのシステムの中核となる超高速並列計算機である。本稿では、このシステムの構成要素についての概要を述べる。
横川 三津夫; 谷 啓二
RIST News, (30), p.24 - 30, 2000/10
宇宙開発事業団、日本原子力研究所及び海洋科学技術センターは、現在、高度な数値シミュレーションにより全地球レベルの複雑な諸現象を計算機上で忠実に再現するために必要な超高速並列計算機システム「地球シミュレータ」の開発を実施している。地球シミュレータ研究開発センターは、この開発を共同で実施するための共同事務所であり、平成10年度に現在の体制が整備された。本稿では、地球シミュレータ研究開発センターが実施している地球シミュレータ開発について紹介する。
横川 三津夫; 谷 啓二
情報処理, 41(4), p.369 - 374, 2000/04
科学技術庁では、プロセス(基礎科学)研究、観測、計算機シミュレーションの三位一体で地球環境変動予測研究を推進するプロジェクトを平成9年度より推進している。その一環として、大気大循環シミュレーションで実効性能5TFLOPS(ピーク性能40TFLOPS)の超高速並列計算機「地球シミュレータ」を開発中である。この地球シミュレータのハードウェア、基本ソフトウェア、応用ソフトウェアについてその概要を解説する。
谷 啓二; 横川 三津夫
情報処理, 41(3), p.249 - 254, 2000/03
科学技術庁では、プロセス(基礎科学)研究、観測、計算機シミュレーションの三位一体で地球環境変動予測研究を推進するプロジェクトを平成9年度より推進している。その一環として、大気大循環シミュレーションで実効性能5TFLOPS(ピーク性能40TFLOPS)の超高速並列計算機「地球シミュレータ」を開発中である。この地球シミュレータの開発の必要性、応用ターゲット、そのために求められる計算機としての要件、開発スケジュール、さらには、世界の高性能計算機開発計画における位置付けなどについて解説する。
横川 三津夫; 津田 義典*; 斉藤 実*; 末広 謙二*
Proceedings of 4th Annual HPF User Group Meeting (HUG2000), p.124 - 130, 2000/00
地球シミュレータのようなSMPクラスタではメモリ階層を考慮した並列化手法を用いる必要があり、ハイブリッド並列プログラミング手法はSMPクラスタ上で大規模計算を行うときに非常に重要である。一様等方性乱流プログラムTrans6に対し、HPFを用いた並列化を行い、自動並列化による実行時の性能比較を、SX-5を用いて実施した。この結果、8個のHPFプロセスの実行時間は、自動並列化による8個のマイクロタスクの実行時間よりも1.58倍大きいことがわかった。また並列化効率は、HPF,マイクロタスクそれぞれで69.87%,44.35%であった。さらに、マルチノードでのプログラミングを検討するために、1つのHPFプロセスとその中の8個のマイクロタスクによる実行時間を計測した結果、8台で約5倍の性能が得られた。
谷 啓二; 松岡 浩; 横川 三津夫; 新宮 哲*; 北脇 重宗*; 三好 甫
Proceedings of 4th International Conference on Supercomputing in Nuclear Applications (SNA 2000) (CD-ROM), 8 Pages, 2000/00
科学技術庁が推進している地球環境変動予測研究計画の一環として、大気大循環シミュレーション分野の現用計算機の1000倍の実効速度を持つ超高速計算機「地球シミュレータ」の開発を宇宙開発事業団と海洋科学技術センターと協力して進めている。そのハードウェア、基本ソフトウェア、応用ソフトウェア開発の現状及びサイト整備の状況について発表する。
横川 三津夫; 新宮 哲*; 萩原 孝*; 磯部 洋子*; 高橋 正樹*; 河合 伸一*; 谷 啓二; 三好 甫*
情報処理学会研究報告, 99(21), p.55 - 60, 1999/00
地球シミュレータは、640台の計算ノードをクロスバネットワークで結合した分散メモリ型並列計算機である。それぞれの計算ノードは、16GBの主記憶装置を8個のベクトル計算機で共有しており、全体のピーク性能は40Tflop/s、主記憶容量は10TBである。地球シミュレータによるプログラムの実効性能を推定するため、地球シミュレータとそれに類似の計算機の動作をシミュレートできるソフトウェアシミュレータ(GSSS)を開発した。いくつかの基本的なプログラムを実行した処理時間について、実測値と推定値を比較した結果、平均で約1%の相対誤差が得られた。また、地球シミュレータの単体プロセッサによる基本的なプログラムの実効速度を推定した結果、平均で4.18Gflop/sが得られた。
横川 三津夫; 幅田 伸一*; 河合 伸一*; 伊藤 寛行*; 谷 啓二; 三好 甫*
Lecture Notes in Computer Science, 1615, p.269 - 280, 1999/00
地球シミュレータ研究開発が1997年に開始された。現在までに基本設計が終了している。基本設計の結果、地球シミュレータは、640台の計算ノードをクロスバスイッチで結合した分散メモリ型並列計算機である。各計算ノードは8台のベクトルプロセッサが共有メモリと結合されている。全体のピーク性能は40テラフロップス、総メモリ容量は10TBである。本稿では、地球シミュレータの概念、基本設計の結果について述べる。
清水 大志; 佐々木 誠*; 市原 潔*; 岸田 則生*; 鈴木 惣一朗*; 佐藤 滋*; 田中 靖久*; 横川 三津夫; 蕪木 英雄
情報処理学会研究報告, 96(81), p.129 - 134, 1996/08
近年、演算回路素子等の速度向上が限界となりつつあるために、並列計算は大規模数値シミュレーションの分野において重要な手法となっており、効率及び移植性の良い並列ライブラリが必要とされている。そこで、我々は各種計算機に対応可能であるMPIまたはPVMを用いた分散メモリ型ベクトル並列計算機数値計算ライブラリの開発を行っている。本論文ではHouseholder変換による三重対角化及び2分法を用いた実密対称行列の固有値問題解法ルーチンの開発について報告する。行列のデータは列方向サイクリック方式により分割し、プロセッサ間のデータ転送量を減らすため対称行列の全ての成分を格納する。Householder変換について8プロセッサを使用した並列化による速度向上率は2000 2000行列に対してParagonで6.0倍である。VPP300では40004000行列に対して4.2倍の値を得た。
2000行列に対してParagonで6.0倍である。VPP300では40004000行列に対して4.2倍の値を得た。
田中 靖久*; 横川 三津夫; 蕪木 英雄
計算工学講演会論文集, 1(1), p.105 - 108, 1996/05
短距離力分子動力学法(MD)プログラムをベクトル並列化し、MDのベクトル並列化手法を検討した。並列化は分散メモリ型ベクトル並列計算機である富士通VPP500上で行った。有力なベクトル化手法として知られるLayered Link Cell法をベースにしたベアリストの分割と粒子分割法を組み合わせた並列化手法を検討し、その並列化アルゴリズムの性能評価を行い、その特性を明らかにした。並列化アルゴリズム全体の性能評価を行った後、粒子数N=32000、プロセッサ数P=16の場合の並列化効率は約62.8%で、速度向上比は約10.0倍であった。
市原 潔*; 横川 三津夫; 蕪木 英雄
計算工学講演会論文集, 1(1), p.377 - 380, 1996/05
3次元非圧縮性流体コードに現われる圧力ポアソン方程式の並列化の例を示す。解法として赤黒SOR法、PCG法をとりあげ、ベクトル並列計算機VPP500において、スケーラビリティの評価を行った。赤黒SOR法については、スカラ並列計算機Paragonにおいても並列化を行い、VPP500におけるスピードアップ率と比較した。Paragonの場合は、スケーラビリティを阻害する要因が通信時間の増大のみであるのに対し、VPP500の場合は、それに加えてベクトル化率の低減化が関与することが定量的に示された。また、PCG法の場合は、DOループに含まれる演算のベクトル長が短いために、DOループ分割によるスケーラビリティの阻害がより顕著に現われることが判明した。
岸田 則生*; 横川 三津夫; 渡辺 正; 蕪木 英雄
計算工学講演会論文集, 1(1), p.117 - 120, 1996/05
2次元Rayleigh-Benard流れに対する直接シミュレーションモンテカルロコードであるPstc-2dをIntel Paragon上で並列化した。並列化により大規模なメモリ空間が利用可能となり、今まで実行できなかったアスペクト比が8のシミュレーションを実行できた。シミュレーション結果は連続体モデルの予測結果と良く一致しており、DSMC法が連続流に近い流れの解析にも適応可能なことが判明した。並列化はParagon固有の並列化ライブラリであるNXライブラリとPVMを用いて行った。DSMC法は通信量が大きいので並列化性能はあまり良くなく、新たな並列計算向きのアルゴリズムの開発が必要なことも判明した。
鈴木 惣一朗*; 横川 三津夫; 蕪木 英雄
計算工学講演会論文集, 1(1), p.101 - 104, 1996/05
Lattice Boltzmann法を用いた2次元流体シミュレーションコードをベクトル並列計算機富士通VPP500およびスカラ並列計算機Intel Paragon XP/S上で開発した。ベクトル並列で95.1%(11521152グリッド、16プロセッサ)、スカラ並列で88.6%(800800グリッド、100プロセッサ)の高並列化効率が得られた。ベクトル並列計算で、プロセッサあたりの計算領域をメモリの上限にとりプロセッサ数に比例して全計算領域を増加させた場合、プロセッサ数を数百台に増加しても計算時間は数パーセントしか増加しないことがパフォーマンスモデルを用いた予測から分かった。
