


長谷川 雄太 
![]()
 ; 今村 俊幸*; 伊奈 拓也 ; 小野寺 直幸
; 今村 俊幸*; 伊奈 拓也 ; 小野寺 直幸 ![]() ; 朝比 祐一
; 朝比 祐一 ![]() ; 井戸村 泰宏
; 井戸村 泰宏 ![]()
Hasegawa, Yuta; Imamura, Toshiyuki*; Ina, Takuya; Onodera, Naoyuki; Asahi, Yuichi; Idomura, Yasuhiro
格子ボルツマン法(LBM)に基づく数値流体力学シミュレーションおよび局所アンサンブル変換カルマンフィルタ(LETKF)によるアンサンブルデータ同化をNVIDIA A100 GPU搭載スパコンに対して実装し、および最適化した。LBMとLETKFの協働のため、データ転置通信を実装し、LETKFのデータ依存性に基づいて計算,ファイルI/O、および通信のオーバーラップにより通信を最適化した。2次元等方乱流,アンサンブル数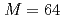 ,格子点数
,格子点数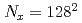 の条件において、通信を最適化した実装は、LETKFを並列化しない単純な実装に対して3.85倍の高速化を達成した。LETKFの主要な計算カーネルは
の条件において、通信を最適化した実装は、LETKFを並列化しない単純な実装に対して3.85倍の高速化を達成した。LETKFの主要な計算カーネルは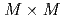 の実対称密行列の固有値分解であり、その計算のため、バッチ形式固有値分解ソルバEigenGを新たに開発した。EigenGによるバッチ形式固有値分解は、既存ライブラリであるcuSolverに対して64倍の高速化を達成した。
の実対称密行列の固有値分解であり、その計算のため、バッチ形式固有値分解ソルバEigenGを新たに開発した。EigenGによるバッチ形式固有値分解は、既存ライブラリであるcuSolverに対して64倍の高速化を達成した。
The ensemble data assimilation of computational fluid dynamics simulations based on the lattice Boltzmann method (LBM) and the local ensemble transform Kalman filter (LETKF) is implemented and optimized on a GPU supercomputer based on NVIDIA A100 GPUs. To connect the LBM and LETKF parts, data transpose communication is optimized by overlapping computation, file I/O, and communication based on data dependency in each LETKF kernel. In two dimensional forced isotropic turbulence simulations with the ensemble size of and the number of grid points of , the optimized implementation achieved 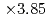 speedup from the naive implementation, in which the LETKF part is not parallelized. The main computing kernel of the local problem is the eigenvalue decomposition (EVD) of real symmetric dense matrices, which is computed by a newly developed batched EVD in EigenG. The batched EVD in EigenG outperforms that in cuSolver, and
speedup from the naive implementation, in which the LETKF part is not parallelized. The main computing kernel of the local problem is the eigenvalue decomposition (EVD) of real symmetric dense matrices, which is computed by a newly developed batched EVD in EigenG. The batched EVD in EigenG outperforms that in cuSolver, and 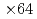 speedup was achieved.
speedup was achieved.
発表言語 |
: | English |
|---|---|---|
掲載資料名 |
: | |
巻 |
: | |
号 |
: | |
ページ数 |
: | p.10 - 17 |
発行年月 |
: | 2022/00 |
発表会議名 |
: | |
開催年月 |
: | 2022/11 |
開催都市 |
: | Dallas (online) |
開催国 |
: | U.S.A. |
キーワード |
: | Data Assimilation; Local Ensemble Transform Kalman Filter; Lattice Boltzmann Method; GPU |
論文URL |
: |
|
|---|---|---|
使用施設 |
: | |
論文解説記事 |
: | GPUを駆使して流体解析と観測データを高速に同化する手法の開発[ |
受委託・共同研究相手機関 |
: |
Access |
: |
- Accesses |
|---|---|---|
Altmetrics |
: |
[CLARIVATE ANALYTICS], [WEB OF SCIENCE], [HIGHLY CITED PAPER & CUP LOGO] and [HOT PAPER & FIRE LOGO] are trademarks of Clarivate Analytics, and/or its affiliated company or companies, and used herein by permission and/or license.
