


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
朝比 祐一; Padioleau, T.*; Latu, G.*; Bigot, J.*; Grandgirard, V.*; Obrejan, K.*
第36回数値流体力学シンポジウム講演論文集(インターネット), 8 Pages, 2022/12
本論文では、運動論的プラズマシミュレーションコードを例としてC++ parallel algorithm (stdpar)による性能可搬実装について論じる。言語標準の並列アルゴリズムstdparと抽象的高次元配列mdspanにより、可読性および生産性を損なわずに性能可搬な実装が可能であることを示す。抽象化により性能可搬性を実現するKokkosや、指示行によって性能可搬性を実現するOpenMPとの比較により、stdparの性能,可搬性,生産性などを論じる。Intel Icelake, NVIDIA V100およびA100 GPUにおいて、stdpar版のアプリケーションの性能はKokkos版に対し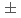 20%の範囲であった。将来的にAMDやIntel GPUにおいて利用可能になるという前提であれば、stdparはエクサスパコンにおいて有力な高生産かつ性能可搬な実装手法となり得る。
20%の範囲であった。将来的にAMDやIntel GPUにおいて利用可能になるという前提であれば、stdparはエクサスパコンにおいて有力な高生産かつ性能可搬な実装手法となり得る。
朝比 祐一; Padioleau, T.*; Latu, G.*; Bigot, J.*; Grandgirard, V.*; Obrejan, K.*
Proceedings of 2022 International Workshop on Performance, Portability, and Productivity in HPC (P3HPC) (Internet), p.68 - 80, 2022/11
被引用回数:0 パーセンタイル:0(Computer Science, Theory & Methods)本論文では、C++ parallel algorithmによる性能可搬な運動論的プラズマシミュレーションコードの実装について論じる。言語標準の並列アルゴリズムstdparと抽象的高次元配列mdspanにより、可読性および生産性を損なわずに性能可搬な実装が可能であることを示す。Intel Icelake、NVIDIA V100およびA100 GPUにおいて、アプリケーションの性能はKokkos版に対し 20%の範囲であった。将来的にAMDやIntel GPUにおいて利用可能になるという前提であれば、C++ parallel algorithmはエクサスパコンにおいて有力な高生産かつ性能可搬な実装手法となり得る。
朝比 祐一; Latu, G.*; Bigot, J.*; Grandgirard, V.*
Proceedings of 2021 International Workshop on Performance, Portability, and Productivity in HPC (P3HPC) (Internet), p.79 - 91, 2021/11
本論文では、性能可搬な運動論的プラズマシミュレーションコードのための最適化手法について論じる。まず、性能可搬ライブラリKokkosと指示行(OpenACC/OpenMP)により、単一実装でCPU、GPUで実行可能な運動論的プラズマシミュレーションコードを開発した。これに最適化を施し、Intelや富士通のCPUおよびNvidia GPUにおいて最適化の効果を評価した。その結果、OpenACC/OpenMPでは1.07倍から1.39倍の性能向上が見られ、Kokkos版では、1.00倍から1.33倍の性能向上が見られた。複数の実装による様々なカーネルの最適化手法の効果を多数のデバイスにおいて調査した本成果は、最適化手法として幅広く利用可能と言える。Kokkosは複数のデータ構造やループ構造を単一コードによって表現することに長けており、CPUとGPU両方において高い性能を発揮するために適したフレームワークであると確認した。
朝比 祐一; 藤井 恵介*; Heim, D. M.*; 前山 伸也*; Garbet, X.*; Grandgirard, V.*; Sarazin, Y.*; Dif-Pradalier, G.*; 井戸村 泰宏; 矢木 雅敏*
Physics of Plasmas, 28(1), p.012304_1 - 012304_21, 2021/01
被引用回数:4 パーセンタイル:43.17(Physics, Fluids & Plasmas)プラズマ乱流の運動論的シミュレーションによって得られた5次元分布関数の時系列データに主成分分析を適用した。これにより、3桁におよぶデータ圧縮を実現しつつ、83%の累積寄与率を保持できた。各主成分ごとの熱輸送への寄与を調べることで、雪崩的熱輸送には速度空間の共鳴構造が関連していることが明らかとなった。
朝比 祐一; Latu, G.*; Bigot, J.*; Grandgirard, V.*
Proceedings of Joint International Conference on Supercomputing in Nuclear Applications + Monte Carlo 2020 (SNA + MC 2020), p.218 - 224, 2020/10
エクサスケール計算機時代には、CPUやGPUの種類を問わずに高性能を発揮する性能可搬性が重要となることが予想される。発表者は、どのような技術を活用すれば運動論的モデルを採用するプラズマ乱流コードの高可搬性実装が可能となるかを調べた。運動論的コードの例として仏国CEAで開発されたGYSELAコードに着目し、当該コードを特徴付ける高次元性(4次元以上)とSemi-Lagrangianスキームといった特徴を抽出したミニアプリケーションを作成した。発表者はミニアプリケーションをOpenACC, OpenMP4.5およびKokkosを用いて並列化し、それぞれの手法の利点,欠点を調査した。OpenACCおよびOpenMP4.5は指示行を挿入することで、Kokkosは高レベルな抽象化を行うことで性能可搬実装を実現する。発表では、生産性,可読性,性能可搬性の観点からそれぞれの手法の利点,欠点を論じる。
朝比 祐一*; Latu, G.*; Bigot, J.*; 前山 伸也*; Grandgirard, V.*; 井戸村 泰宏
Concurrency and Computation; Practice and Experience, 32(5), p.e5551_1 - e5551_21, 2020/03
被引用回数:1 パーセンタイル:14.03(Computer Science, Software Engineering)2つのジャイロ運動論コード、GYSELA, GKVを最新のアクセラレータ環境、Xeon Phi KNL, Tesla P100 GPUに移植した。一台のSkylakeプロセッサーに比べ、KNLにおけるGYSELAの逐次計算カーネルは1.3x、P100 GPUにおけるGKVの逐次計算カーネルは7.4x高速化された。GYSELAとGKVのスケーリングテストをそれぞれ16-512 KNLおよび32-256 P100 GPUで実施し、GYSELAのセミラグランジアンカーネルおよびGKVの畳み込みカーネルにおけるデータ転置通信が主要なボトルネックとなることがわかった。この通信コストを削減するために、これらのコードにパイプライン法およびタスク並列法に基づく通信オーバーラップを実装した。
朝比 祐一*; Grandgirard, V.*; Sarazin, Y.*; Donnel, P.*; Garbet, X.*; 井戸村 泰宏; Dif-Pradalier, G.*; Latu, G.*
Plasma Physics and Controlled Fusion, 61(6), p.065015_1 - 065015_15, 2019/05
被引用回数:4 パーセンタイル:27.12(Physics, Fluids & Plasmas)Full-fジャイロ運動論コードGYSELAを用いて輸送過程へのポロイダル対流セルの影響を調べた。この目的のために、対流セルのフィルタを適用し、フィルタ有無のシミュレーション結果を比較した。フィルタを適用することで磁気ドリフトに駆動されるエネルギー束が半減することがわかった。対流セルの周波数スペクトは乱流レイノルズ応力テンソルの周波数と対応し、対流セルが乱流によって駆動されることを示した。この対流セルの効果は乱流と新古典のダイナミクスの相互作用と考えられる。
朝比 祐一*; Grandgirard, V.*; 井戸村 泰宏; Garbet, X.*; Latu, G.*; Sarazin, Y.*; Dif-Pradalier, G.*; Donnel, P.*; Ehrlacher, C.*
Physics of Plasmas, 24(10), p.102515_1 - 102515_17, 2017/10
被引用回数:7 パーセンタイル:37.55(Physics, Fluids & Plasmas)トカマクプラズマにおける熱流駆動型のイオン温度勾配乱流を計算するために2つの大域的full-Fジャイロ運動論コードのベンチマークを行う。この目的のために、full-Fジャイロ運動論方程式を現実的な熱流束固定条件で計算するセミ・ラグランジアンコードGYSELA、および、オイラーコードGT5Dを採用する。時空間特性に注目して雪崩的な輸送現象を評価した。自己組織化臨界現象(SOC)的な振舞いを議論するために統計解析を実施し、両方のコードで高周波側で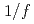 スペクトルから
スペクトルから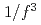 スペクトルへの遷移を確認した。このベンチマークに基づき、SOC的な振舞いは数値計算法に依存しないロバーストな特徴であることを検証した。
スペクトルへの遷移を確認した。このベンチマークに基づき、SOC的な振舞いは数値計算法に依存しないロバーストな特徴であることを検証した。
朝比 祐一*; Latu, G.*; 伊奈 拓也; 井戸村 泰宏; Grandgirard, V.*; Garbet, X.*
IEEE Transactions on Parallel and Distributed Systems, 28(7), p.1974 - 1988, 2017/07
被引用回数:7 パーセンタイル:55.4(Computer Science, Theory & Methods)セミ・ラグランジュ法における間接メモリアクセス、有限差分法におけるストライドメモリアクセスといった複雑なメモリアクセスパターンを有する核融合プラズマ乱流コードの高次元ステンシル計算をGPGPUやXeon Phiプロセッサ等の演算加速器上で最適化した。どちらのデバイスでも、Array of Structure of Array (AOSOA)データレイアウトが連続的なメモリアクセスに有効である。Xeon Phiでは時空間データ局所性の向上によるローカルキャッシュの効率的利用が必要不可欠である。GPGPUではテクスチャメモリの利用がセミ・ラグランジュ法の間接メモリアクセス性能を向上する。これらの最適化により、アクセラレータ用核融合カーネルはCPU用カーネルに比べてSandy Bridge (CPU)用最適化コードに比べて1.4x - 8.1x高速化した。
Villard, L.*; Bottino, A.*; Brunner, S.*; Casati, A.*; Chowdhury, J.*; Dannert, T.*; Ganesh, R.*; Garbet, X.*; G rler, T.*; Grandgirard, V.*; et al.
rler, T.*; Grandgirard, V.*; et al.
Plasma Physics and Controlled Fusion, 52(12), p.124038_1 - 124038_18, 2010/11
被引用回数:18 パーセンタイル:56.51(Physics, Fluids & Plasmas)This paper presents some of the main recent advances in gyrokinetic theory and computing of turbulence. A past controversy regarding the finite size (finite 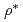 ) effect in ITG turbulence has now been resolved. Now, both Eulerian and Lagrangian global codes are shown to agree and to converge to the flux-tube result in the
) effect in ITG turbulence has now been resolved. Now, both Eulerian and Lagrangian global codes are shown to agree and to converge to the flux-tube result in the 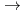 0 limit. It is found, however, that an appropriate treatment of geometrical terms is necessary. Turbulent processes are characterized by a chaotic behavior, often accompanied by bursts and avalanches. Performing ensemble averages of statistically independent simulations, starting from different initial conditions, is presented as a way to assess the intrinsic variability of turbulent fluxes and obtain reliable estimates of the standard deviation.
0 limit. It is found, however, that an appropriate treatment of geometrical terms is necessary. Turbulent processes are characterized by a chaotic behavior, often accompanied by bursts and avalanches. Performing ensemble averages of statistically independent simulations, starting from different initial conditions, is presented as a way to assess the intrinsic variability of turbulent fluxes and obtain reliable estimates of the standard deviation.
朝比 祐一; Latu, G.*; 伊奈 拓也; 井戸村 泰宏; Grandgirard, V.*; Garbet, X.*
no journal, ,
テラフロップス級のメニーコアアーキテクチャにおいて、核融合プラズマコード、GYSELA、GT5Dのカーネル最適化を行った。本研究で用いたアーキテクチャは、アクセラレータ(Xeon Phi、GPU)と最新型のマルチコアCPU (FX100)である。GYSELAカーネルは、セミラグランジアンスキームを用いており、高い演算密度を有する。GYSELAカーネルのXeon Phi上での最適化を通じ、Xeon Phiにおいて有効なコードのベクトル化の重要性を示す。一方、GT5Dカーネルは差分法に用いており、複雑なメモリ読み込みの効率化が欠かせない。GT5DカーネルのGPU上での最適化を通じ、GPU上で有効なshared memoryを用いたメモリアクセスの効率化手法を示す。
朝比 祐一; 井戸村 泰宏; 伊奈 拓也; Garbet, X.*; Grandgirard, V.*; Latu, G.*
no journal, ,
Delta-fジャイロ運動論的シミュレーションと呼ばれる従来のプラズマ乱流シミュレーションでは、背景のプラズマと揺動のプラズマのスケール分離が仮定され揺動のプラズマの時間発展のみが計算された。これに対し、Full-fジャイロ運動論的シミュレーションでは、背景のプラズマと揺動のプラズマを第一原理的に同時に発展させるため、従来扱えなかった自己無頓着なプラズマ分布と乱流の相互作用という物理を扱うことができる。Delta-fジャイロ運動論的シミュレーションコードは多数存在し、コード間ベンチマークは盛んに行われてきた。それによって計算自体のロバスト性が確保されているが、Full-fシミュレーションにおいては、物理的複雑さゆえ、系統的なベンチマークは行われていない。発表では、機構および外部機関において独立に開発されたFull-fジャイロ運動論的シミュレーションコード間のベンチマークの進展状況および課題について論じる。
朝比 祐一*; Garbet, X.*; 井戸村 泰宏; Grandgirard, V.*; Latu, G.*; Sarazin, Y.*; Dif-Pradalier, G.*; Donnel, P.*; Ehrlacher, C.*; Passeron, Ch.*
no journal, ,
CEAおよび原子力機構で開発した2つの大域的full-fジャイロ運動論コードのベンチマークを実施した。イオン温度勾配駆動モードの線形安定性、帯状流の線形減衰、衝突性輸送といった線形過程については2つのコード間の定量的一致を確認した。非線形乱流シミュレーションの予備的なベンチマークでは境界条件や熱源モデル等の計算モデルの違いに起因する計算結果の違いを確認し、今後の定量的な非線形ベンチマークに向けた課題を明らかにした。
朝比 祐一*; Latu, G.*; 伊奈 拓也; 井戸村 泰宏; Grandgirard, V.*; Garbet, X.*
no journal, ,
セミ・ラグランジュ法, 有限差分法といったステンシル計算に基づく核融合プラズマ乱流コードの計算カーネルをGPUGPU, Xeon Phi, FX100といった最新メニーコアプロセッサ上で最適化し、1.4x - 8.1xの処理性能向上を達成した。数値計算法によって異なるメモリアクセスパターンと各ハードウェアのメモリ-キャッシュ機構の親和性を確認し、各環境で異なる最適化技術を開発した。XeonPhiではスレッド間のロードバランスを向上し、ローカルキャッシュ有効利用のための最適化技術を開発した。GPGPUではテクスチャメモリを活用した最適化技術やレジスタを再利用する実装を開発した。一方、FX100では従来のCPU向け最適化をそのまま利用できることがわかった。
朝比 祐一*; Grandgirard, V.*; 井戸村 泰宏; Sarazin, Y.*; Latu, G.*; Garbet, X.*
no journal, ,
本講演では、平成27年度-28年度に実施したBMTFFプロジェクトの研究成果を概説する。本プロジェクトでは、full-fジャイロ運動論モデルのしっかりした基盤を確立するために、EUと日本の2つの主要full-fジャイロ運動論コード、GYSELAおよびGT5Dのベンチマークを実施した。平成27年度には全ての数値的実装の検証を行い、境界条件が同じになるようにコードを修正した。この修正により、衝突性輸送、線形帯状流減衰、イオン温度勾配駆動(ITG)モードの線形安定性のベンチマークに成功した。平成28年度は両方のコードに同じソースとシンクのモデルを実装し、非線形乱流計算のベンチマークを実施した。熱源のない減衰ITG乱流計算は同様の分布緩和過程を示し、非線形臨界温度勾配が互いに定量的に一致することを確認した。一方、熱源を含む駆動ITG乱流計算は雪崩的輸送の間欠的バーストを示し、同様の1/fタイプの周波数スペクトルを確認した。
朝比 祐一; Latu, G.*; Bigot, J.*; Grandgirard, V.*
no journal, ,
性能可搬な運動論的プラズマシミュレーションコードの実現に向けて、単純化されたミニアプリを開発し、それを性能可搬ライブラリKokkosと指示行によってCPU, GPUで並列実行可能にした。可搬性を高めるため、Kokkosと指示行実装どちらにおいてもコードをCPUとGPUで別途実装することは避け、単一実装でCPU, GPUで並列実行可能とした。開発したミニアプリの性能を富士通A64FX, Nvidia GPUおよびIntel CPUで性能測定した。これらのアーキテクチャはエクサスケールスーパコンピュータにおいて主要な候補になっている。NvidiaやIntelにおいては良好な性能が得られたものの、A64FXにおいてはメモリの間接参照により大幅に性能が大幅劣化することが明らかとなった。講演では、可読性や生産性を高めるためのKokkosや指示行での実装方法についても論じる。
Grandgirard, V.*; 朝比 祐一; Bigot, J.*; Bourne, E.*; Dif-Pradalier, G.*; Donnel, P.*; Garbet, X.*; Ghendrih, P.*
no journal, ,
将来の核融合装置のためにはプラズマ乱流輸送や熱輸送を理解することが重要である。プラズマコアの乱流については非線形の5次元ジャイロ運動論コードによってモデル化可能である。一方で、境界壁付近のプラズマのエッジ領域のモデル化は困難となっている。これらを同時にモデル化するためにはエクサスケール計算機が必須である。エクサスケール計算の準備として、OpenMP4.5taskレベル並列に関する取り組みや、Kokkosによる性能可搬実装のためのコード再設計について説明する。
朝比 祐一; 前山 伸也*; Bigot, J.*; Garbet, X.*; Grandgirard, V.*; 藤井 恵介*; 下川辺 隆史*; 渡邉 智彦*; 井戸村 泰宏; 小野寺 直幸; et al.
no journal, ,
大規模流体シミュレーションのためのin-situデータ解析手法およびdeep learningによる流体シミュレーション結果の代理モデルを開発した。新たに開発したin-situデータ処理手法では、MPIアプリとpythonのポスト処理スクリプトが弱結合される。この手法によってファイルを経由しないポスト処理が可能となり、最大2.7倍の性能向上が見られた。また、多重解像度の流れ場予測を可能にするdeep learning代理モデルを開発した。本モデルでは、十分な予測精度と数値シミュレーションに対する大幅な速度向上を実現した。
朝比 祐一; 前山 伸也*; Bigot, J.*; Garbet, X.*; Grandgirard, V.*; Obrejan, K.*; Padioleau, T.*; 藤井 恵介*; 下川辺 隆史*; 渡邉 智彦*; et al.
no journal, ,
エクサスケール数値計算のための性能可搬性向上に関する研究を紹介する。特にAMD GPUにおけるプラズマコードの性能や、C++標準言語におけるGPUコードの性能評価結果を示す。またdeep learningを用いた流体計算の代理モデルについても紹介する。
朝比 祐一; 前山 伸也*; Bigot, J.*; Garbet, X.*; Grandgirard, V.*; Obrejan, K.*; Padioleau, T.*; 藤井 恵介*; 下川辺 隆史*; 渡邉 智彦*; et al.
no journal, ,
エクサスケール数値計算のための性能可搬性向上に関する研究を紹介する。特にAMD GPUにおけるプラズマコードの性能や、C++標準言語におけるGPUコードの性能評価結果を示す。またdeep learningを用いた流体計算の代理モデルについても紹介する。
朝比 祐一; 長谷川 雄太; Padioleau, T.*; Millan, A.*; Bigot, J.*; Grandgirard, V.*; Obrejan, K.*
no journal, ,
一般に、実稼働可能な科学シミュレーションは、計算、通信、ファイルI/Oを含む多くの異なるタスクで構成される。GPUによる計算の高速化に比べて、通信とファイルI/Oは遅くなり、大きなボトルネックになりうる。これらのコストを抑えるためには、これらのタスクを並行して管理することが非常に重要である。本講演では、通信とファイルI/Oのコストをマスクするために、言語標準C++ senders/receiversを採用する。ケーススタディとして、局所アンサンブル変換カルマンフィルタ(LETKF)を用いた2次元乱流シミュレーションコードをC++ senders/receiversを用いて実装する。LETKFでは、模擬観測データはファイルから読み込まれ、その後、MPI通信とGPU上での密行列演算が行われる。このフレームワークによる性能移植が可能なことと、非同期処理による性能向上の効果を実証する。

