


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
長谷川 雄太; 青木 尊之*; 小林 宏充*; 井戸村 泰宏; 小野寺 直幸
Parallel Computing, 108, p.102851_1 - 102851_12, 2021/12
被引用回数:7 パーセンタイル:50.25(Computer Science, Theory & Methods)GPUスーパコンピュータに対して格子ボルツマン法(LBM: lattice Botltzmann method)およびforest-of-octreesに基づくブロック構造型の局所細分化格子(LMR: local mesh refinement)を用いた空力解析コードを実装し、その性能を評価した。性能評価の結果、従来の空間充填曲線(SFC; space-filling curve)に基づく領域分割アルゴリズムでは、本空力解析において袖領域通信のコストが過大となることがわかった。領域分割の改善手法として本稿では挿し木法を提案し、領域分割の局所性とトポロジーを改善し、従来のSFCに基づく手法に比べて通信コストを1/3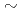 1/4に削減した。強スケーリング測定では、最大で1.82倍の高速化を示し、128GPUで2207MLUPS(mega-lattice update per second)の性能を達成した。弱スケーリング測定では、8128GPUで93.4%の並列化効率を示し、最大規模の128GPU計算では44.73億格子点を用いて9620MLUPSの性能を達成した。
1/4に削減した。強スケーリング測定では、最大で1.82倍の高速化を示し、128GPUで2207MLUPS(mega-lattice update per second)の性能を達成した。弱スケーリング測定では、8128GPUで93.4%の並列化効率を示し、最大規模の128GPU計算では44.73億格子点を用いて9620MLUPSの性能を達成した。
山田 進; 町田 昌彦; 今村 俊幸*
Parallel Computing; Technology Trends, p.105 - 113, 2020/00
被引用回数:1 パーセンタイル:28.96(Computer Science, Hardware & Architecture)本発表は科学研究費補助金(科研費)に従い実施した強相関ハバードモデル計算に現れる固有値問題に対する高性能計算に関するものである。具体的には、ハバードモデルの計算に現れる固有値計算に固有値計算ソルバの1つであるLOBPCG法を適用した際の高速化についての発表である。特筆すべき成果は、現在主流のプロセッサの1つであるGPUのアーキテクチャに合わせたデータの格納方法を提案し、実際に行列計算を高速化したことである。さらに、複数の線形計算をまとめて実行することで、データへのアクセス回数を減らすことができ、さらなる高速化も実現した。これらの高速化により、これまでの方法と比較し全体で約1.4倍の高速化を実現した。なお、この成果は科研費研究「エクサスケール計算機を想定した量子モデルシミュレーションに対する並列化・高速化」の研究成果である一方、GPUを利用した高性能計算にも資する成果である。
山田 進; 今村 俊幸*; 町田 昌彦
Parallel Computing is Everywhere, p.27 - 36, 2018/00
本発表は科研費研究の一環として実施した固有値計算ソルバLOBPCG法の前処理に関する研究についての発表である。LOBPCG法は反復解法であり適切な前処理を用いることで収束性が向上することが知られているが、量子問題に表れるハバードモデルの固有値を計算する際に物理パラメータによっては既存の前処理では収束性が向上しないことがある。そこで、線形方程式の反復解法で前処理として使われているノイマン展開を利用した前処理を適用し、そのような問題に対しても収束性が向上することを見出した。さらに、問題の物理的性質を考慮し、演算回数は若干増加するが、通信回数を減少させる方法を提案した。この方法で開発したコードを、原子力機構の並列計算機SGI ICEXを用いて並列シミュレーションしたところ、これまでの方法よりも約20%高速に計算できることを確認した。この成果は、固有値問題に有効な前処理方法を見出しただけではなく、ネットワーク構造が複雑化してきている並列計算機での性能向上にも資する成果である。
山田 進; 今村 俊幸*; 町田 昌彦
Parallel Computing; On the Road to Exascale, p.361 - 369, 2016/00
被引用回数:1 パーセンタイル:40.39(Computer Science, Hardware & Architecture)本発表では簡単な演算を高速に実行できるアクセラレータ(補助演算装置)の1つであるGPUを用いてハバードモデルの計算に現れる固有値問題を高速に計算する手法について発表する。特筆すべき成果は、ハバードモデルの物理的性質、およびGPUの構造を考慮してデータの格納形式や計算方法を考案したところ、GPUで一般的に利用されている計算方法よりも約2倍高速に計算できることを実際のGPUを利用した計算から示したことである。さらに、6コアのCPUを用いた並列計算と比較しても、23倍高速に計算できることを確認した。この成果は、今後高性能計算において主流になると考えられているアクセラレータを利用した計算機の有効利用に資する成果である。
前山 伸也; 渡邉 智彦*; 井戸村 泰宏; 仲田 資季; 沼波 政倫*; 石澤 明宏*
Parallel Computing, 49, p.1 - 12, 2015/11
被引用回数:7 パーセンタイル:49.67(Computer Science, Theory & Methods)Optimization techniques of a plasma turbulence simulation code GKV for improved strong scaling are presented. This work is motivated by multi-scale plasma turbulence extending over multiple spatio-temporal scales of electrons and ions, whose simulations based on the gyrokinetic theory require huge calculations of five-dimensional (5D) computational fluid dynamics by means of spectral and finite difference methods. First, we present the multi-layer domain decomposition of the multi-dimensional and multi-species problem, and segmented MPI-process mapping on 3D torus interconnects, which fully utilizes the bi-section bandwidth for data transpose and reduces the conflicts of simultaneous point-to-point communications. These techniques reduce the inter-node communication cost drastically. Second, pipelined computation-communication overlaps are implemented by using the OpenMP/MPI hybrid parallelization, which effectively mask the communication cost. Thanks to the above optimizations, GKV achieves excellent strong scaling up to 600 k cores with high effective parallelization rate 99.99994% on K, which demonstrates its applicability and efficiency toward a million of cores. The optimized code realizes multi-scale plasma turbulence simulations covering electron and ion scales, and reveals cross-scale interactions of electron- and ion-scale turbulence.
山田 進; 今村 俊幸*; 町田 昌彦
Parallel Computing; Accelerating Computational Science and Engineering (CSE), p.427 - 436, 2014/03
本発表は、科学研究費補助金研究課題に従い実施した多軌道強相関クラスタハバードモデル計算に現れる固有値計算ソルバの並列化を行う際の通信手法の最適化に関するものである。特筆すべき成果は、上記のモデルの物理的性質及び現在主流の並列計算機のアーキテクチャを考慮して並列化のための通信手法を提案し、実際に高性能計算を可能にしたことである。通常のハバードモデルのシミュレーションコードに対しては、アップスピンとダウンスピンを独立に扱える性質を利用して並列化・高速化を行うが、今回対象にした多軌道モデルでは、アップスピンとダウンスピンが同時に動くケースも考える必要があるため、これまでの方法では並列化ができなかった。そこで、モデルを分割する並列化方法を提案した。また、この並列化の際にデータを適切に分割することで、通信の競合を回避できることを指摘し、実際にこの通信手法が有効であることを原子力機構のBX900において確認した。なお、この成果は科学研究費補助金研究課題「2次元量子モデルに対するメニーコア並列計算機向き並列化・高速化手法の研究開発」の研究成果である一方、原子力材料のマルチスケールシミュレーション研究開発にも資する成果である。
櫛田 慶幸
Proceedings of 20th Euromicro International Conference on Parallel, Distributed and Network-Based Computing (PDP 2012), p.7 - 8, 2012/02
GPGPU及びマルチコアプロセッサーを用いたインフラサウンド伝搬及び放射性核種輸送計算の高速化について述べる。これらのシミュレーションプログラムは包括的核実験禁止条約準備機関のミッションである核実験の発見をサポートするもので、セキュリティの問題があることから単一のワークステーションで実行されている。したがって、GPGPUやマルチコアプロセッサーのような高性能計算機を用いて高速化することで、より信頼性の高い計算を行うことができるようになる。研究の結果、インフラサウンドシミュレーションでは偏微分方程式に基づく伝搬計算法を18.3倍高速化し、簡易化計算と同程度の時間で終了できるようにした。また、核種輸送計算では今までは事実上不可能であった北半球全域の計算を可能とすることができた。
櫛田 慶幸
Proceedings of 19th Euromicro International Conference on Parallel, Distributed and Network-Based Computing (PDP 2011), p.401 - 408, 2011/02
本研究では核融合シミュレーションに代表される、原子力分野のシミュレーションに必須である有限要素法について、非均質マルチコアプロセッサー(HMP)に適した新しい実装法を開発した。また、新しい実装法が理論的な性能解析からも有効であることを示した。HMPは米Intel社を含む多くのプロセッサーベンダーが製品化しており、次世代スーパーコンピューティングに使われることが確実である。しかしながら、その理論性能を達成するためには新しいプログラミング手法が必要であることがわかっており、早い段階で手法を確立することが望まれている。特に問題となっているのは、高い計算能力を持つ一方でプロセッサーへのデータ供給能力が相対的に低い点である。そのため、データの転送量及び見かけ上の転送時間を減らすことで全体の速度向上を図っている。この実装法をポワッソン方程式を例題にして実装し、従来手法との比較を行った。結果、新実装は、従来プロセッサーにおける従来の実装に比べて10倍の性能を示した。このため、新実装法はHMPのように高い計算能力と比較的低いデータ供給能力を持つプロセッサーに対して有効であることが示された。
櫛田 慶幸; 武宮 博; 徳田 伸二*
Proceedings of 18th Euromicro International Conference on Parallel, Distributed and Network-Based Computing (PDP 2010), p.482 - 488, 2010/02
本研究では、高い計算能力を持ち2009年10月現在世界最高性能のスーパーコンピューターであるRoadrunnerにも搭載されているCellプロセッサーを使うことで、核融合モニタリングシステムに必要不可欠な高速固有値解析システムを開発した。核融合モニタリングシステムのための固有値解析システム構築は次の二つの理由で、現在のスーパーコンピュータでは困難であった。(1)スーパーコンピューターはユーザーが占有できる時間が限られており、モニタリングに必要な時間の間利用できない。(2)現在のスーパーコンピューターはネットワークで多数の計算ユニットを接続する形式であるが、これではネットワークによるオーバーヘッドが大きくモニタリングシステムに必要な時間解像度から考えられる計算時間に計算を終わらせることができない。そのため本研究では、価格性能比が高く、現在の計算ユニットよりも高速なCellプロセッサーを用いることで困難を克服し、モニタリングシステムに必要な計算速度を持ちながら、スーパーコンピューターよりも遥かに低価格で構築できるシステムを構築した。論文では、Cellを利用するために必要なプログラムの詳細とシステムの性能について述べる。
山田 知典
Parallel, Distributed and Grid Computing for Engineering, p.439 - 454, 2009/04
安定なエネルギー供給を保証するため、原子力発電の重要性は広く認知されている。日本国内では2006年の耐震設計審査指針の改訂、2007年新潟県中越沖地震における設計で想定した地震動を上回る地震動の観測など地震時における原子力プラント健全性評価への注目が集まっている。本発表では日本原子力研究開発機構システム計算科学センターで行っている耐震シミュレーションの概要と本シミュレーションにおける計算戦略について発表を行う。
Kim, G.; 鈴木 喜雄; 手島 直哉; 西田 明美; 山田 知典; 新谷 文将; 武宮 博; 中島 憲宏; 近藤 誠
Proceedings of 1st International Conference on Parallel, Distributed and Grid Computing for Engineering (PARENG 2009) (CD-ROM), 12 Pages, 2009/04
We developed the Script Generator API to support users to develop Grid-enabled client application. The Script Generator API automatically generates a Grid-enabled workflow script needed to execute jobs on a Grid system. Using the Script Generator API enables users to use a Grid environment without consciousness of a Grid computing system. In this paper, we show the implementation of the Script Generator API in our Grid infrastructure and its utilization to the Full-scale 3D Vibration Simulator for an Entire Nuclear Power Plant. By developing a Grid-enabled client application for the Full-scale 3D Vibration Simulator, we confirmed the usability of the Script Generator API.
山田 進; 奥村 雅彦; 町田 昌彦
Proceedings of IASTED International Conference on Parallel and Distributed Computing and Networks (PDCN 2008), p.175 - 180, 2008/02
量子多体問題を計算するのに有効な方法として密度行列繰り込み群(DMRG)がある。DMRG法は本来1次元の量子多体モデル用に開発されたが、理論的には、直接2次元量子多体モデルにも拡張することができる。しかしながら、使用するメモリが指数関数的に増加するため、2次元モデルへの直接的拡張には並列化が必須である。そこで、発表者らはDMRGで扱うモデルに規則性があることを発見し、その規則性を利用した並列計算方法を考案した。実際に、2次元モデルに対するDMRG法を考案方法で並列化し、Altix3700Bx2上で並列シミュレーションしたところ、効率的な並列計算が可能であることが確認できた。また、並列計算により4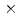 40サイトというこれまでDMRG法で直接計算することのできなかった大きさのモデルを、直接計算することに成功した。
40サイトというこれまでDMRG法で直接計算することのできなかった大きさのモデルを、直接計算することに成功した。
山田 進; 今村 俊幸*; 町田 昌彦
Proceedings of 23rd IASTED International Multi-Conference on Parallel and Distributed Computing and Networks (PDCN 2005), p.638 - 643, 2005/02
通信量の多いアプリケーションである強相関フェルミ粒子系問題に現れる超大規模なハミルトニアン行列に対する地球シミュレータ向きの固有値計算プログラムの開発を行った。地球シミュレータは、MPIを利用したノード間の通信処理を演算処理で隠蔽することができないため、通信量の多いアプリケーションではその性能を引き出すことが困難である。そこで、本研究ではノード内並列機能とMPIを組合せることにより、通信処理を演算で隠蔽できる通信手法を提案した。実際にこの通信手法を適用することにより、通常の通信手法を利用した場合より約1.4倍高速化することが確認できた。これにより、世界最大級である1200億次元のハミルトニアン行列の最小固有値を約4分で計算することに成功した。また、10TFLOPSを超える計算性能を達成した。
小出 洋; 平山 俊雄; 村杉 明夫*; 林 拓也*; 笠原 博徳*
Int. Conf. on Supercomputing,Workshop 1;Scheduling Algorithms for Parallel-Distributed Computing, p.63 - 69, 1999/00
メタスケジューリング手法の目的は、異機種並列計算機クラスタを使用した、ひとつの科学計算プログラムの計算時間の最小化である。メタスケジューリング手法では、逐次プログラムから、サブルーチンやループ等のマクロタスクを生成するため、OSCARマルチグレイン並列化コンパイラを使用する。資源情報サーバから得られる異機種並列計算機クラスタの負荷に関する情報とコンパイル時に得られるマクロタスクの予測処理時間を使用し、マクロタスクを異機種並列計算機クラスタに動的スケジューリングする。COMPACSのDNYX,SX-4,SR2201,SR2201小型モデル上で、トカマク・プラズマの電場/粒子連成シミュレーションに、メタスケジューリングを適用し、性能評価を行った結果、SX-4の負荷が高いとき、マクロタスクは、SR2201,SR2201小型モデルに自動的に分散され、SX-4一台で計算を行った場合よりも22.7%計算時間が短縮された。
今村 俊幸; 徳田 伸二
Proceedings of IASTED International Conference on Parallel and Distributed Computing and Systems, p.583 - 588, 1999/00
ネットワーク上の計算資源を自在に組み合わせ仮想的な計算機を構築するメタコンピューティングと呼ばれる計算手法の応用として、数値トカマクにおいて用いられるハイブリッドコードを2台の異なる並列計算機を同時に用いて計算を行った。本手法では、計算機間でのタイト(密)な通信を行う必要があるが、それを実現するために、異機種間通信ライブラリStampiを利用している。本論文では、異機種間通信ライブラリStampiの紹介とともにハイブリッドコードの異機種間使用の結果を示している。現状のOSもしくはハードウェアの制限から、速度面での向上は見られなかったが、ネットワークの性能が4倍程度向上した場合に単一計算機を上回ることが予測された。また、3台以上の異機種計算機へのマッピングも可能であり、より大規模な計算への可能性を有することを示した。
浅井 清
Int. Symp. on Parallel Computing in Engineering and Science, 0, 10 Pages, 1997/00
当センターでのこの1年余りの研究開発の成果の紹介を行った。それらは、(1)OSとユーザとの柔軟なインターフェイスを取るSTA基本ソフト、(2)並列機用数値計算ライブラリ、(3)格子生成ソフト、(4)実時間可視化ソフト、(5)2相流の相変化・超伝導物質の磁束状態・乱流のエネルギー散逸構造に関する数値実験などである。
太田 高志*
Scientific Computing in Object-Oriented Parallel Environments, p.211 - 217, 1997/00
並列科学計算のためのオブジェクト指向による、プログラミングのフレームワークを提案する。異なる並列実行環境に対して、同一の計算プログラムを適用出来るように並列プログラムを構成する。これにより、プログラム開発の効率を向上すると共に、再利用性、拡張、改変性を良くすることが可能となる。
高野 誠; 坂本 浩紀; 増川 史洋
Proc. of the 3rd Parallel Computing Workshop; PCW 94, 0, p.P2.G.1 - P2.G.9, 1994/00
遮蔽解析に使用するモンテカルロコードの並列化に関する研究について示した。並列処理で使用する乱数としてLeap Frog法が使用されることがあるが、この手法が並列用乱数としては不適当であることがわかった。代案として、スカラー計算機で使用されている乱数ルーチンを、並列機上で不都合なく利用する方法を示した。遮蔽解析用モンテカルロコードMCACEとMCNP-4コードを並列化し、分散メモリ型並列機上で実行したところ、80%以上の並列化効率を示した。また、FORTRAN言語とUNIXコマンドのみを使って並列処理を行う手法を開発し、NFS環境下で複数のワークステーションによる並列処理が可能であることを示した。並列版モンテカルロコードの利用方法として、アナログモンテカルロ法及び数値実験の可能性について検討した。
高野 誠; 増川 史洋; 坂本 浩紀*
Proc. of the 2nd Parallel Computing Workshop; PCW 93, p.P2-P-1 - P2-P-5, 1993/00
遮蔽解析では、連続エネルギ断面積を使用したモンテカルロ法により、今の所、最も詳細な結果がえられると考えられる。しかしながら、従来の計算機の能力では、種々の分散低減手法を使用する必要があり、これら手法を適切に用いるためには十分な経験が必要とされた。本報では、最近の並列計算機の高速処理能力を使って、分散低減手法を排したアナログモンテカルロ計算による遮蔽解析を試みた。
竹田 辰興; 谷 啓二; 常松 俊秀; 岸本 泰明; 栗田 源一; 松下 智*; 中田 登志之*
Parallel Computing, 18, p.743 - 765, 1992/00
被引用回数:2 パーセンタイル:47.38(Computer Science, Theory & Methods)核融合炉開発計画に必要な理論的データベースを充実するためにプラズマ・シミュレータMETISが設計されプロトタイプ・プラズマ・シミュレータProtoMETISが製作された。METISは250台のプロセッサ要素からなる分散メモリ型MIMDタイプ並列計算機として設計されトカマク・プラズマの非線形MHD挙動および磁場リップルによるアルファ粒子損失の計算を行うよう最適化されている。ProtoMETISを用いて、上記問題に対するMETIS構成の性能を評価して満足すべき結果を得た。また、自由電子レーザーのシミュレーション及びトカマク・プラズマのMHD平衡計算もプラズマ・シミュレータ上で効率よく実行できることが確認できた。
増川 史洋; 高野 誠; 内藤 俶孝; 川添 明美*; 奥田 基*
Proc. of the 1st Annual Users Meeting of Fujitsu Parallel Computing Research Facilities, p.P1-A-1 - P1-A-8, 1992/00
遮蔽安全評価用モンテカルロコードMCACEを並列計算機上で実行できるように並列化を行ない、並列化による計算速度の向上の度合を富士通の並列計算実験機AP-1000で測定した。バッチあたりの粒子数10240で512バッチの計算を512個のプロセッサを並列に用いて行った時、475.6倍の速度倍率が得られた。また、この時の並列化効率は92.9%であった。並列化効率を低下させる主要因は、粒子のランダムウォークに起因するものであり、これはバッチあたりの粒子数を増やすことで軽減される。本測定でMCACEの並列化は、理想的に行われている事が明らかとなった。
