


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Sitompul, Y.; 杉原 健太; 小野寺 直幸; 井戸村 泰宏
EPJ Web of Conferences, 302, p.05004_1 - 05004_10, 2024/10
被引用回数:1 パーセンタイル:94.62(Computer Science, Interdisciplinary Applications)高速炉の設計では、自由表面渦によるガス巻き込み現象を回避することが極めて重要である。数値解析は、これらの現象を理解するための重要な手法の一つである。しかしながら、従来の数値解析手法では計算効率や精度に課題があったため、計算効率と複雑な流れのシミュレーション能力で知られる格子ボルツマン法(LBM)を代替手法として採用する。本研究では、ガス巻込み解析を高速化するために自由表面流LBMを実装し、従来の手法と比較して精度を維持しながら計算コストを大幅に削減した。LBMを用いたシミュレーション結果は実験データとよく一致し、将来の高速炉設計における解析の高速化に有望な手段を提供する。
杉原 健太; 小野寺 直幸; Sitompul, Y.; 井戸村 泰宏; 山下 晋
EPJ Web of Conferences, 302, p.03002_1 - 03002_10, 2024/10
被引用回数:1 パーセンタイル:0.00(Computer Science, Interdisciplinary Applications)従来の界面捕捉法を用いた気液二相流のシミュレーションでは、気泡が互いに反発することを示す実験的証拠にもかかわらず、気泡が互いに近づくと数値的には合体する傾向があることが観察された。逐次的な数値合体が流動様式に与える影響が大きいことを考慮すると、近接した気泡の合体挙動を制御する必要がある。この問題に対処するため、各気泡に独立した流体率を適用することで気泡合体を抑制するMulti-Phase Field(MPF)法を導入した。本研究では、3重点における表面相互作用に関連する数値誤差を最小化するために、N-phaseモデルに基づくMPFを採用した。さらに、Ordered Active Parameter Tracking法を実装し、数百の流体率を効率的に格納した。MPF法を検証するために、円管内気泡流の解析を実施し、Colinらの実験データと比較した。検証結果は、気泡分布と流速分布に関して妥当な一致を示した。
長谷川 雄太; 井戸村 泰宏; 小野寺 直幸
EPJ Web of Conferences, 302, p.03005_1 - 03005_9, 2024/10
被引用回数:0 パーセンタイル:0.00(Computer Science, Interdisciplinary Applications)乱流計算を対象とした格子ボルツマン法に、局所アンサンブル変換カルマンフィルタ(LETKF)に基づくアンサンブルデータ同化を実装した。LETKFおよびLBMは全てGPUで実装されており、最新のGPUスパコンで効率的に計算可能である。データ同化の精度検証として3次元単一角柱周りの流れの実験を行った。実験より、本手法は空間および時間的に粗い観測データを用いた場合でも精度の良いデータ同化を行うことができると示された。すなわち、時間間隔をカルマン渦周期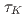 の2分の1、空間解像度を角柱直径
の2分の1、空間解像度を角柱直径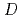 の16分の1(計算格子点数の1.56%)として速度場を観測した時、観測ノイズよりも小さいデータ同化誤差を達成した。
の16分の1(計算格子点数の1.56%)として速度場を観測した時、観測ノイズよりも小さいデータ同化誤差を達成した。
渡辺 力*; 石川 修平*; 川島 正行*; 下山 宏*; 小野寺 直幸; 長谷川 雄太; 稲垣 厚至*
Journal of Wind Engineering and Industrial Aerodynamics, 250, p.105783_1 - 105783_17, 2024/07
被引用回数:3 パーセンタイル:68.80(Engineering, Civil)ラグランジュ粒子分散モデルとラージ・エディ・シミュレーション(LES)コードを組み合わせた漂流雪のシミュレーションを実施した。このモデルは、質量輸送率の流速依存性や粒径分布の変動といった観測された特徴を正確に再現した。また、従来の推定に反して、跳躍層の高さは流速とともに単調に増加することを示した。さらに、推定された跳躍層の高さ付近で跳躍から浮遊への移行が確認され、密な雪の流れが表面近傍流の小規模な低速ストリークと関連していることがわかった。
小野寺 直幸; 杉原 健太; 伊奈 拓也; 井戸村 泰宏
計算工学講演会論文集(CD-ROM), 29, 3 Pages, 2024/06
気液二相流体解析は炉設計や安全性評価に適用できるなど、原子力工学分野において重要な研究テーマの一つである。しかしながら、これらの解析はマルチスケールの大規模計算を必要とし、先進的な数値手法が必須となる。この課題の解決に向けて、多相多成分熱流動解析コードJUPITERに対するPoisson解法の開発を進めてきた。本研究では、非圧縮性の近似を行わないNavier-Stokes方程式の定式化により、陰的な時間発展で現れる圧力Poisson方程式の行列を優対角とすることで、行列の反復計算の収束性の改善を目指した。円管内の気泡流解析において、8台のGPUを用いた収束性能測定では、非圧縮性近似を行ったものに対して、半分の計算時間および収束回数となり、本研究の定式化の有用性が示された。
長谷川 雄太; 井戸村 泰宏; 小野寺 直幸
計算工学講演会論文集(CD-ROM), 29, 4 Pages, 2024/06
局所アンサンブル変換カルマンフィルタおよび細分化格子ボルツマン法(LBM-LETKF)による乱流のアンサンブルデータ同化を実装した。検証として、3次元角柱周りの乱流に対するデータ同化の精度を調べた。観測間隔をカルマン渦列の周期の半分、観測点数を計算格子点の0.195%とした条件において、データ同化誤差は観測ノイズと同等以下に収まった。これにより、LBM-LETKFが空間的・時間的に疎な観測に対するデータ同化を可能にすることが示された。
長谷川 雄太; 小野寺 直幸; 朝比 祐一; 伊奈 拓也; 今村 俊幸*; 井戸村 泰宏
Fluid Dynamics Research, 55(6), p.065501_1 - 065501_25, 2023/11
被引用回数:1 パーセンタイル:13.13(Mechanics)格子ボルツマン法(LBM)に基づくラージエディーシミュレーション(LES)に対するデータ同化の適用性を調査した。2次元等方乱流の観測システムシミュレーション実験を行い、空間的に疎かつノイズを含む観測を用いてナッジング法及び局所アンサンブル変換カルマンフィルタによるデータ同化の精度を検証した。LETKFの利点として、ナッジングで必要となる空間補間及び巨視的量(流体密度及び流速)からLBMの速度分布関数への変換を必要としないことが挙げられる。計算条件として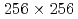 格子及び10%の流速観測ノイズを設定した実験では、64アンサンブルのLETKFは
格子及び10%の流速観測ノイズを設定した実験では、64アンサンブルのLETKFは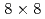 の観測点(計算格子点数に対して0.1%程度)でも観測ノイズよりも小さい誤差を示した。これは、ナッジングで同様の精度を示すのに1桁程度多くの観測点数を要する精度である。さらに、LETKFでは観測点数の不足はエネルギースペクトルの振幅には影響せず、スペクトルの位相誤差のみに影響することが確認された。以上の結果により、LETKFは、空間的に疎かつノイズを含む観測を用いた2次元のLBM計算のデータ同化に対してロバストかつ高精度であることが示された。
の観測点(計算格子点数に対して0.1%程度)でも観測ノイズよりも小さい誤差を示した。これは、ナッジングで同様の精度を示すのに1桁程度多くの観測点数を要する精度である。さらに、LETKFでは観測点数の不足はエネルギースペクトルの振幅には影響せず、スペクトルの位相誤差のみに影響することが確認された。以上の結果により、LETKFは、空間的に疎かつノイズを含む観測を用いた2次元のLBM計算のデータ同化に対してロバストかつ高精度であることが示された。
杉原 健太; 小野寺 直幸; 井戸村 泰宏; 山下 晋
JAEA-Research 2023-006, 47 Pages, 2023/10
 JAEA-Research-2023-006.pdf:3.28MB
JAEA-Research-2023-006.pdf:3.28MB
本報告書では、気液二相流シミュレーションのためのフェーズフィールドモデルに基づく新しい界面捕獲法を提案する。従来のフェーズフィールドモデルでは、界面補正強度パラメータは計算領域内の最大流速から決定されていたが、界面補正は空間全体に一様に適用されているため、補正を必要としない位置にも適用されていた。新手法では、フェーズフィールド変数あるいはフェーズフィールドモデルの強度に空間分布を持つように拡張し、局所的な流速場に応じた最適なパラメータを設定できるようにした。また、界面移流試験や気泡上昇計算の誤差解析を用いた系統的なパラメータスキャンに基づき、最適なフェーズフィールドパラメータを導出する手法を提案する。気液二相流のベンチマークテストを通じて、提案モデルを検証し、提案モデルが従来のフェーズフィールドモデルよりも高精度であることを示す。
小野寺 直幸; 井戸村 泰宏; 長谷川 雄太; 朝比 祐一; 稲垣 厚至*; 下瀬 健一*; 平野 洪賓*
計算工学講演会論文集(CD-ROM), 28, 4 Pages, 2023/05
高度計算機技術開発室では、都市全域を含む広域の風況場から細かな路地等を捉えたマルチスケールの風況シミュレーションコードCityLBMの開発を進めている。CityLBMは、格子ボルツマン法に適合細分化格子を適用した省メモリ化、および、GPUスーパーコンピュータによる高性能計算により、数km四方に対してリアルタイムのアンサンブルシミュレーションが可能となる。一方、実現象には、モデル化できない複雑な境界条件が含まれているため、観測データをシミュレーションに反映させるためのデータ同化技術が必要である。本研究では、現実の風況を再現するために、アンサンブルカルマンフィルターに基づく地表面温度バイアスの最適化手法を提案した。CityLBMの検証として、東京都心部を対象とした観測システムシミュレーション実験を実施し、地表面近傍の温度から、境界条件として与えている地表面温度を推定する。
長谷川 雄太; 小野寺 直幸; 朝比 祐一; 井戸村 泰宏
計算工学講演会論文集(CD-ROM), 28, 5 Pages, 2023/05
格子ボルツマン法と局所アンサンブル変換カルマンフィルタ(LBM-LETKF)を用いた二次元等方乱流のデータ同化を実装した。計算条件として、格子点数を256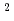 、観測点数を256またはそれよりも粗い解像度、速度の観測値に印加するノイズを系の速度のRMSに対して10%、アンサンブル数を4、16または64に設定し、データ同化実験をおこなった。データ同化実験の結果、LETKFの精度は、観測点が密な場合と疎な場合のいずれも、ナッジング法よりも優れていることが示された。LETKFは、観測点が不足している場合に数値的に不安定になるが、このような不安定性はアンサンブル数を増やすことで抑制できた。64アンサンブル、8
、観測点数を256またはそれよりも粗い解像度、速度の観測値に印加するノイズを系の速度のRMSに対して10%、アンサンブル数を4、16または64に設定し、データ同化実験をおこなった。データ同化実験の結果、LETKFの精度は、観測点が密な場合と疎な場合のいずれも、ナッジング法よりも優れていることが示された。LETKFは、観測点が不足している場合に数値的に不安定になるが、このような不安定性はアンサンブル数を増やすことで抑制できた。64アンサンブル、8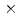 8の疎な観測の条件においては、LBM-LETKFの速度の二乗平均平方根誤差(RMSE)は観測ノイズのRMSよりも小さく、その精度はナッジング法でより多くの観測点(3232)を用いた場合と同等であった。以上により、LETKFは、アンサンブル数が十分大きければ、高精度かつロバストであり、したがって、LBMを用いた乱流のデータ同化に適していることが示された。
8の疎な観測の条件においては、LBM-LETKFの速度の二乗平均平方根誤差(RMSE)は観測ノイズのRMSよりも小さく、その精度はナッジング法でより多くの観測点(3232)を用いた場合と同等であった。以上により、LETKFは、アンサンブル数が十分大きければ、高精度かつロバストであり、したがって、LBMを用いた乱流のデータ同化に適していることが示された。
朝比 祐一; 小野寺 直幸; 長谷川 雄太; 下川辺 隆史*; 芝 隼人*; 井戸村 泰宏
Boundary-Layer Meteorology, 186(3), p.659 - 692, 2023/03
被引用回数:2 パーセンタイル:25.47(Meteorology & Atmospheric Sciences)定点観測された風向などの時系列データおよび汚染物質放出点を入力として、汚染物質の地表面拡散分布を予測する機械学習モデルを開発した。問題設定としては、一様風が都市部へ流入し、都市部内にランダムに設置された汚染物質放出点から汚染物質が拡散するという状況を扱っている。機械学習モデルとしては、汚染物質放出点から汚染物質の拡散分布を予測するCNNモデルを用いた。風向などの時系列データは、Transformerや多層パーセプトロンによってEncodeし、CNNへと引き渡す。これによって、現実的に取得可能な定点測時系列データのみを入力とし、実用上価値の高い汚染物質の地表面拡散分布の予測を可能とした。同一のモデルを用いて定点観測時系列データから汚染物質放出点の予測が可能であることも示した。
中山 浩成; 小野寺 直幸; 佐藤 大樹
Isotope News, (785), p.20 - 23, 2023/02
LHADDASは、現実気象条件下で建物影響を考慮した放射性物質の大気拡散の詳細評価が可能なLOHDIM-LES、建物遮蔽効果を考慮して迅速に空間線量率評価が可能なSIBYL、及び都市大気拡散の即時解析が可能なCityLBMの計算コードを統合したシステムであり、ユーザの目的に応じて計算コードの柔軟な選択が可能である。このため、LHADDASは、原子力施設の立地審査のための従来手法に代わるより現実的な事前解析、原子力緊急時対応のための対策立案や影響評価、都市市街地拡散テロにおける即時解析など局所域大気拡散の様々な課題の解決に活用できる有用性を有する。LHADDASは、放出率・気象データ・地理情報データ・線量率寄与応答関数の入力ファイルの処理や計算条件等の入力データの設定を行うプリプロセス、LOHDIM-LES・CityLBMによる大気拡散計算のためのソルバー、SIBYLによる空間線量率空間分布を詳細評価するポストプロセスの3つのパートにより構成されている。計算シミュレーションに必要な入出力ファイルを整合させ、それらを公開データから生成可能とすることで、簡易工程でシミュレーション実行が可能な統合システムを完成させた。
伊奈 拓也; 井戸村 泰宏; 今村 俊幸*; 小野寺 直幸
Proceedings of International Conference on High Performance Computing in Asia-Pacific Region (HPC Asia 2023) (Internet), p.29 - 34, 2023/02
ヤコビ前処理による混合精度クリロフソルバは、ヤコビ前処理をFP16やBF16のような低精度で計算した場合しばしば著しい収束性の悪化を示すことがある。この収束性の悪化はデータ変換時の丸め誤差により対角優位性が失われることに起因することがわかった。この問題を解決するために、元の行列データの対角優位性を保つように設計された新しいデータ変換方法を提案する。NVIDIA V100 GPU上でポアソン方程式を共役勾配法、双共役勾配安定化法、一般化最小残差法にFP16/BF16ヤコビ前処理を組み合わせた混合精度クリロフソルバによって計算することによって提案手法を検証する。データ変換はCUDAの組み込み関数を利用して最近接丸め、正の無限大丸め、負の無限大丸め、ゼロ方向丸めを切り替えて実装し、これが主反復の前に一度だけ呼び出される。したがって、提案するデータ変換にかかるコストは無視できる程度に小さい。連立一次方程式をスケーリングして行列の係数を連続的に変化させた場合に、最近接丸めによる従来のデータ変換では、対角係数と非対角係数の丸め誤差に依存して収束性が周期的に変化する。ここで、収束性悪化の周期と大きさは仮数部のビット長に依存する。一方、提案するデータ変換方式では収束性悪化を完全に回避できることが示され、ヤコビ前処理において余分なコストを伴わないロバストな混合精度計算が可能となった。
長谷川 雄太; 小野寺 直幸; 朝比 祐一; 井戸村 泰宏
第36回数値流体力学シンポジウム講演論文集(インターネット), 5 Pages, 2022/12
格子ボルツマン法と局所アンサンブル変換カルマンフィルタ(LBM-LETKF)による乱流のアンサンブルデータ同化をGPUに実装し、精度の検証を行なった。32GPUを用いて、格子点数2.3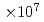 、アンサンブル数32の条件で、3次元角柱周りの流れ対してデータ同化実験を実施した。本実験におけるデータ同化の時間間隔は、カルマン渦周期の半分に設定した。精度として、揚力係数の誤差(normalized mean absolute error; NMAE)を測定したところ、データ同化なし、ナッジング法(より単純なデータ同化手法)による同化、およびLETKFのそれぞれにおいて、誤差は132%, 148%、および13.2%であった。これにより、観測頻度が低い本計算条件においては、ナッジング法のような簡易な手法では解に系統的な遅れが現れてデータ同化の精度を保つことができない一方で、LETKFでは良好なデータ同化精度を示すことが確認できた。
、アンサンブル数32の条件で、3次元角柱周りの流れ対してデータ同化実験を実施した。本実験におけるデータ同化の時間間隔は、カルマン渦周期の半分に設定した。精度として、揚力係数の誤差(normalized mean absolute error; NMAE)を測定したところ、データ同化なし、ナッジング法(より単純なデータ同化手法)による同化、およびLETKFのそれぞれにおいて、誤差は132%, 148%、および13.2%であった。これにより、観測頻度が低い本計算条件においては、ナッジング法のような簡易な手法では解に系統的な遅れが現れてデータ同化の精度を保つことができない一方で、LETKFでは良好なデータ同化精度を示すことが確認できた。
小野寺 直幸; 井戸村 泰宏; 長谷川 雄太; 中山 浩成
第36回数値流体力学シンポジウム講演論文集(インターネット), 3 Pages, 2022/12
高解像度の風況解析は、スマートシティ設計に活用できるなど非常に重要である。都市部は高層ビルが密集した複雑な形状をしており、それらにより風の流れが乱流状態となるため、都市街区全域から細かな路地までを捉えた大規模計算が必要である。それらの課題に対して、本研究グループは、メソスケール気象データを境界条件として利用したマルチスケールの汚染物質拡散手法CityLBMコードの開発を進めている。CityLBMは、計算領域周辺の境界条件をメソスケール気象データに同化させるナッジング法を導入することで、現実の風況を反映した解析が可能である。しかしながら、従来のナッジング法では、ナッジング係数が一定のため、大気状態が変化するような長時間解析の乱流強度を再現できない問題点が挙げられる。本研究では、アンサンブルカルマンフィルタを用いた動的なナッジング・パラメータの最適化手法を提案する。CityLBMの検証として、米国オクラホマシティの風況実験に対する解析を実施した。シミュレーションと観測のそれぞれで得られる乱流強度の誤差を低減するようにナッジング係数を更新した結果、一定のナッジング係数の結果と比較して10%ほど予測精度を向上することを確認した。
杉原 健太; 小野寺 直幸; 井戸村 泰宏; 山下 晋
第36回数値流体力学シンポジウム講演論文集(インターネット), 5 Pages, 2022/12
本報告ではConservative Allen-Cahn型のMulti-Phase Field(MPF)法をベースに、個別の相の保存性も保証する保存型MPF法を提案し、2次元の界面移流計算による保存性検証テストを実施し保存できていることを確認した。保存型MPF法を水平に配置された2つの気泡上昇計算に適用し、Duineveldらの実験における気泡の反発現象をZhangらの計算の1/50の解像度で再現可能であることが分かった。
中山 浩成; 小野寺 直幸; 佐藤 大樹; 永井 晴康; 長谷川 雄太; 井戸村 泰宏
Journal of Nuclear Science and Technology, 59(10), p.1314 - 1329, 2022/10
被引用回数:5 パーセンタイル:60.29(Nuclear Science & Technology)放射性物質の大気放出に対して、放出点から数km以内の局所域スケールでの放射性物質の複雑な大気濃度分布及び沈着分布を計算するとともに、それらからの放射線について建物による遮蔽効果を考慮して詳細に線量評価が行える解析システム(LHADDAS)を開発した。本システムは、個々の建物の影響を考慮して詳細に拡散計算が行える局所域高分解能大気拡散計算コード(LOHDIM-LES)、都市域に対して迅速に拡散計算が行えるリアルタイム都市大気拡散計算コード(CityLBM)、建物の遮蔽効果を考慮した3次元体系で放射線の挙動を迅速に計算できる線量評価コード(SIBYL)及び計算に必要となるデータベースと入力作成プログラムから構成されている。本解析システムは、原子力施設の安全審査における風洞実験に代わる現実的な評価手法、原子力事故時の施設内外作業員の被ばく線量評価、都市域での放射性物質拡散テロに対する汚染状況把握と被ばく線量評価など、幅広い活用が期待できる。
長谷川 雄太; 小野寺 直幸; 朝比 祐一; 井戸村 泰宏
計算工学講演会論文集(CD-ROM), 27, 4 Pages, 2022/06
局所アンサンブル変換カルマンフィルタ(LETKF)および格子ボルツマン法(LBM)を用いたアンサンブルデータ同化のGPU実装を行った。D2Q9 LBMによる二次元等方性乱流を対象として、最大32アンサンブルで性能測定を行った。LETKFの計算コストは、8アンサンブルまででLBMと同程度であり、それ以上の大アンサンブル数においてはLBMよりも高くなった。32アンサンブルにおいて、1同化サイクルあたりの所要時間はLBMで5.39ms、LETKFで28.3msであった。これらの結果から、3次元LBMの実用計算に本手法を適用するためにはLETKFの更なる高速化が必要であることが示唆される。
小野寺 直幸; 井戸村 泰宏; 長谷川 雄太; 下川辺 隆史*; 青木 尊之*
計算工学講演会論文集(CD-ROM), 27, 4 Pages, 2022/06
高度計算機技術開発室では、風況デジタルツインの実現に向けて、風況解析コードCityLBMを開発している。CityLBMは、計算領域周辺の境界条件をメソスケール気象データに同化させるナッジング法を導入することで、現実の風況を反映した解析が可能である。しかしながら、従来のナッジング法では、ナッジング係数が一定のため、大気状態が変化するような長時間解析の乱流強度を再現できない問題点が挙げられる。そこで、本研究では、パーティクルフィルタを用いた動的なナッジング・パラメータの最適化手法を提案する。CityLBMの検証として、米国オクラホマシティの風況実験に対する解析を実施した。シミュレーションと観測のそれぞれで得られる乱流強度の誤差を低減するようにナッジング係数を更新した結果、シミュレーションにおいて終日の大気境界層を再現できることを確認した。
朝比 祐一; 小野寺 直幸; 長谷川 雄太; 下川辺 隆史*; 芝 隼人*; 井戸村 泰宏
計算工学講演会論文集(CD-ROM), 27, 5 Pages, 2022/06
都市風況解析コードCityLBMをAMD社のMI100 GPUへと移植し、CityLBMの性能をNVIDIA P100, V100, A100およびAMD MI100において測定した。ホスト間でのMPI通信を利用した場合、CityLBMの性能はMI100においてV100と比べ20%程度向上した。適合細分化格子法に起因する補間カーネルを除く演算カーネルでは、MI100においてV100と比べ性能向上を確認した。
