


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
長谷川 雄太; 小野寺 直幸; 朝比 祐一; 伊奈 拓也; 今村 俊幸*; 井戸村 泰宏
Fluid Dynamics Research, 55(6), p.065501_1 - 065501_25, 2023/11
被引用回数:1 パーセンタイル:13.13(Mechanics)格子ボルツマン法(LBM)に基づくラージエディーシミュレーション(LES)に対するデータ同化の適用性を調査した。2次元等方乱流の観測システムシミュレーション実験を行い、空間的に疎かつノイズを含む観測を用いてナッジング法及び局所アンサンブル変換カルマンフィルタによるデータ同化の精度を検証した。LETKFの利点として、ナッジングで必要となる空間補間及び巨視的量(流体密度及び流速)からLBMの速度分布関数への変換を必要としないことが挙げられる。計算条件として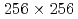 格子及び10%の流速観測ノイズを設定した実験では、64アンサンブルのLETKFは
格子及び10%の流速観測ノイズを設定した実験では、64アンサンブルのLETKFは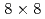 の観測点(計算格子点数に対して0.1%程度)でも観測ノイズよりも小さい誤差を示した。これは、ナッジングで同様の精度を示すのに1桁程度多くの観測点数を要する精度である。さらに、LETKFでは観測点数の不足はエネルギースペクトルの振幅には影響せず、スペクトルの位相誤差のみに影響することが確認された。以上の結果により、LETKFは、空間的に疎かつノイズを含む観測を用いた2次元のLBM計算のデータ同化に対してロバストかつ高精度であることが示された。
の観測点(計算格子点数に対して0.1%程度)でも観測ノイズよりも小さい誤差を示した。これは、ナッジングで同様の精度を示すのに1桁程度多くの観測点数を要する精度である。さらに、LETKFでは観測点数の不足はエネルギースペクトルの振幅には影響せず、スペクトルの位相誤差のみに影響することが確認された。以上の結果により、LETKFは、空間的に疎かつノイズを含む観測を用いた2次元のLBM計算のデータ同化に対してロバストかつ高精度であることが示された。
朝比 祐一; 前山 伸也*; 藤井 恵介*
計算工学講演会論文集(CD-ROM), 28, 4 Pages, 2023/05
本研究では、小スケールに駆動源が存在する系におけるサブグリッドスケール(SGS)モデルをデータ駆動型のアプローチによって構築した。SGSモデルは、Mori-Zwanzigの射影演算子法とニューラルネットワークに基づく手法で構築した。小スケールに駆動源が存在するKuramoto-Sivashinsky乱流について、開発したSGSモデルを利用したLarge Eddy Simulation (LES)を行い乱流スペクトルを比較したところ、大スケールにおいてどちらのモデルもスペクトルがDNSと一致することを確認した。
小野寺 直幸; 井戸村 泰宏; 長谷川 雄太; 朝比 祐一; 稲垣 厚至*; 下瀬 健一*; 平野 洪賓*
計算工学講演会論文集(CD-ROM), 28, 4 Pages, 2023/05
高度計算機技術開発室では、都市全域を含む広域の風況場から細かな路地等を捉えたマルチスケールの風況シミュレーションコードCityLBMの開発を進めている。CityLBMは、格子ボルツマン法に適合細分化格子を適用した省メモリ化、および、GPUスーパーコンピュータによる高性能計算により、数km四方に対してリアルタイムのアンサンブルシミュレーションが可能となる。一方、実現象には、モデル化できない複雑な境界条件が含まれているため、観測データをシミュレーションに反映させるためのデータ同化技術が必要である。本研究では、現実の風況を再現するために、アンサンブルカルマンフィルターに基づく地表面温度バイアスの最適化手法を提案した。CityLBMの検証として、東京都心部を対象とした観測システムシミュレーション実験を実施し、地表面近傍の温度から、境界条件として与えている地表面温度を推定する。
長谷川 雄太; 小野寺 直幸; 朝比 祐一; 井戸村 泰宏
計算工学講演会論文集(CD-ROM), 28, 5 Pages, 2023/05
格子ボルツマン法と局所アンサンブル変換カルマンフィルタ(LBM-LETKF)を用いた二次元等方乱流のデータ同化を実装した。計算条件として、格子点数を256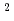 、観測点数を256またはそれよりも粗い解像度、速度の観測値に印加するノイズを系の速度のRMSに対して10%、アンサンブル数を4、16または64に設定し、データ同化実験をおこなった。データ同化実験の結果、LETKFの精度は、観測点が密な場合と疎な場合のいずれも、ナッジング法よりも優れていることが示された。LETKFは、観測点が不足している場合に数値的に不安定になるが、このような不安定性はアンサンブル数を増やすことで抑制できた。64アンサンブル、8
、観測点数を256またはそれよりも粗い解像度、速度の観測値に印加するノイズを系の速度のRMSに対して10%、アンサンブル数を4、16または64に設定し、データ同化実験をおこなった。データ同化実験の結果、LETKFの精度は、観測点が密な場合と疎な場合のいずれも、ナッジング法よりも優れていることが示された。LETKFは、観測点が不足している場合に数値的に不安定になるが、このような不安定性はアンサンブル数を増やすことで抑制できた。64アンサンブル、8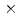 8の疎な観測の条件においては、LBM-LETKFの速度の二乗平均平方根誤差(RMSE)は観測ノイズのRMSよりも小さく、その精度はナッジング法でより多くの観測点(3232)を用いた場合と同等であった。以上により、LETKFは、アンサンブル数が十分大きければ、高精度かつロバストであり、したがって、LBMを用いた乱流のデータ同化に適していることが示された。
8の疎な観測の条件においては、LBM-LETKFの速度の二乗平均平方根誤差(RMSE)は観測ノイズのRMSよりも小さく、その精度はナッジング法でより多くの観測点(3232)を用いた場合と同等であった。以上により、LETKFは、アンサンブル数が十分大きければ、高精度かつロバストであり、したがって、LBMを用いた乱流のデータ同化に適していることが示された。
朝比 祐一; 小野寺 直幸; 長谷川 雄太; 下川辺 隆史*; 芝 隼人*; 井戸村 泰宏
Boundary-Layer Meteorology, 186(3), p.659 - 692, 2023/03
被引用回数:2 パーセンタイル:25.47(Meteorology & Atmospheric Sciences)定点観測された風向などの時系列データおよび汚染物質放出点を入力として、汚染物質の地表面拡散分布を予測する機械学習モデルを開発した。問題設定としては、一様風が都市部へ流入し、都市部内にランダムに設置された汚染物質放出点から汚染物質が拡散するという状況を扱っている。機械学習モデルとしては、汚染物質放出点から汚染物質の拡散分布を予測するCNNモデルを用いた。風向などの時系列データは、Transformerや多層パーセプトロンによってEncodeし、CNNへと引き渡す。これによって、現実的に取得可能な定点測時系列データのみを入力とし、実用上価値の高い汚染物質の地表面拡散分布の予測を可能とした。同一のモデルを用いて定点観測時系列データから汚染物質放出点の予測が可能であることも示した。
長谷川 雄太; 小野寺 直幸; 朝比 祐一; 井戸村 泰宏
第36回数値流体力学シンポジウム講演論文集(インターネット), 5 Pages, 2022/12
格子ボルツマン法と局所アンサンブル変換カルマンフィルタ(LBM-LETKF)による乱流のアンサンブルデータ同化をGPUに実装し、精度の検証を行なった。32GPUを用いて、格子点数2.3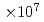 、アンサンブル数32の条件で、3次元角柱周りの流れ対してデータ同化実験を実施した。本実験におけるデータ同化の時間間隔は、カルマン渦周期の半分に設定した。精度として、揚力係数の誤差(normalized mean absolute error; NMAE)を測定したところ、データ同化なし、ナッジング法(より単純なデータ同化手法)による同化、およびLETKFのそれぞれにおいて、誤差は132%, 148%、および13.2%であった。これにより、観測頻度が低い本計算条件においては、ナッジング法のような簡易な手法では解に系統的な遅れが現れてデータ同化の精度を保つことができない一方で、LETKFでは良好なデータ同化精度を示すことが確認できた。
、アンサンブル数32の条件で、3次元角柱周りの流れ対してデータ同化実験を実施した。本実験におけるデータ同化の時間間隔は、カルマン渦周期の半分に設定した。精度として、揚力係数の誤差(normalized mean absolute error; NMAE)を測定したところ、データ同化なし、ナッジング法(より単純なデータ同化手法)による同化、およびLETKFのそれぞれにおいて、誤差は132%, 148%、および13.2%であった。これにより、観測頻度が低い本計算条件においては、ナッジング法のような簡易な手法では解に系統的な遅れが現れてデータ同化の精度を保つことができない一方で、LETKFでは良好なデータ同化精度を示すことが確認できた。
朝比 祐一; Padioleau, T.*; Latu, G.*; Bigot, J.*; Grandgirard, V.*; Obrejan, K.*
第36回数値流体力学シンポジウム講演論文集(インターネット), 8 Pages, 2022/12
本論文では、運動論的プラズマシミュレーションコードを例としてC++ parallel algorithm (stdpar)による性能可搬実装について論じる。言語標準の並列アルゴリズムstdparと抽象的高次元配列mdspanにより、可読性および生産性を損なわずに性能可搬な実装が可能であることを示す。抽象化により性能可搬性を実現するKokkosや、指示行によって性能可搬性を実現するOpenMPとの比較により、stdparの性能,可搬性,生産性などを論じる。Intel Icelake, NVIDIA V100およびA100 GPUにおいて、stdpar版のアプリケーションの性能はKokkos版に対し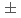 20%の範囲であった。将来的にAMDやIntel GPUにおいて利用可能になるという前提であれば、stdparはエクサスパコンにおいて有力な高生産かつ性能可搬な実装手法となり得る。
20%の範囲であった。将来的にAMDやIntel GPUにおいて利用可能になるという前提であれば、stdparはエクサスパコンにおいて有力な高生産かつ性能可搬な実装手法となり得る。
朝比 祐一; Padioleau, T.*; Latu, G.*; Bigot, J.*; Grandgirard, V.*; Obrejan, K.*
Proceedings of 2022 International Workshop on Performance, Portability, and Productivity in HPC (P3HPC) (Internet), p.68 - 80, 2022/11
被引用回数:6 パーセンタイル:75.01(Computer Science, Theory & Methods)本論文では、C++ parallel algorithmによる性能可搬な運動論的プラズマシミュレーションコードの実装について論じる。言語標準の並列アルゴリズムstdparと抽象的高次元配列mdspanにより、可読性および生産性を損なわずに性能可搬な実装が可能であることを示す。Intel Icelake、NVIDIA V100およびA100 GPUにおいて、アプリケーションの性能はKokkos版に対し 20%の範囲であった。将来的にAMDやIntel GPUにおいて利用可能になるという前提であれば、C++ parallel algorithmはエクサスパコンにおいて有力な高生産かつ性能可搬な実装手法となり得る。
朝比 祐一; 小野寺 直幸; 長谷川 雄太; 下川辺 隆史*; 芝 隼人*; 井戸村 泰宏
計算工学講演会論文集(CD-ROM), 27, 5 Pages, 2022/06
都市風況解析コードCityLBMをAMD社のMI100 GPUへと移植し、CityLBMの性能をNVIDIA P100, V100, A100およびAMD MI100において測定した。ホスト間でのMPI通信を利用した場合、CityLBMの性能はMI100においてV100と比べ20%程度向上した。適合細分化格子法に起因する補間カーネルを除く演算カーネルでは、MI100においてV100と比べ性能向上を確認した。
長谷川 雄太; 小野寺 直幸; 朝比 祐一; 井戸村 泰宏
計算工学講演会論文集(CD-ROM), 27, 4 Pages, 2022/06
局所アンサンブル変換カルマンフィルタ(LETKF)および格子ボルツマン法(LBM)を用いたアンサンブルデータ同化のGPU実装を行った。D2Q9 LBMによる二次元等方性乱流を対象として、最大32アンサンブルで性能測定を行った。LETKFの計算コストは、8アンサンブルまででLBMと同程度であり、それ以上の大アンサンブル数においてはLBMよりも高くなった。32アンサンブルにおいて、1同化サイクルあたりの所要時間はLBMで5.39ms、LETKFで28.3msであった。これらの結果から、3次元LBMの実用計算に本手法を適用するためにはLETKFの更なる高速化が必要であることが示唆される。
前山 伸也*; 渡邉 智彦*; 仲田 資季*; 沼波 政倫*; 朝比 祐一; 石澤 明宏*
Nature Communications (Internet), 13, p.3166_1 - 3166_8, 2022/06
被引用回数:25 パーセンタイル:96.10(Multidisciplinary Sciences)乱流輸送は、磁場閉じ込め核融合プラズマを閉じ込めるための重要な物理過程である。最近の理論的,実験的研究により 小さい(電子)スケールと大きい(イオン)スケールの乱流の間にクロススケールの相互作用が存在することが明らかにされている。従来の乱流輸送モデルではクロススケール相互作用が考慮されていないため、将来の核燃焼プラズマ実験においてクロススケール相互作用を考慮する必要があるかどうかを明らかにする必要がある。核燃焼プラズマ実験では、核融合で生まれたアルファ粒子によって高い電子温度が維持されるため、プラズマの性質が今まで実験されてきたものと大きく異なると予測される。本論文では、スーパーコンピュータを用いたシミュレーションにより、高電子温度プラズマにおける電子スケールの 電子温度プラズマの乱流は、電子だけでなく燃料や灰の乱流輸送にも影響を与えることを明らかにした。電子スケールの乱流は、イオンスケールの微小的不安定性の原因である共鳴電子の軌道を乱し、大きなスケールの乱流揺らぎを抑制する。同時に、イオンスケールの乱流渦も電子スケールの乱流を抑制する。これらの結果は 異なるスケールの乱流が互いに排他的であることを示す。また、クロススケール相互作用により、熱流束が減少する可能性を示す。
長谷川 雄太; 今村 俊幸*; 伊奈 拓也; 小野寺 直幸; 朝比 祐一; 井戸村 泰宏
Proceedings of 13th Workshop on Latest Advances in Scalable Algorithms for Large-Scale Heterogeneous Systems (ScalAH22) (Internet), p.10 - 17, 2022/00
格子ボルツマン法(LBM)に基づく数値流体力学シミュレーションおよび局所アンサンブル変換カルマンフィルタ(LETKF)によるアンサンブルデータ同化をNVIDIA A100 GPU搭載スパコンに対して実装し、および最適化した。LBMとLETKFの協働のため、データ転置通信を実装し、LETKFのデータ依存性に基づいて計算,ファイルI/O、および通信のオーバーラップにより通信を最適化した。2次元等方乱流,アンサンブル数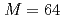 ,格子点数
,格子点数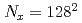 の条件において、通信を最適化した実装は、LETKFを並列化しない単純な実装に対して3.85倍の高速化を達成した。LETKFの主要な計算カーネルは
の条件において、通信を最適化した実装は、LETKFを並列化しない単純な実装に対して3.85倍の高速化を達成した。LETKFの主要な計算カーネルは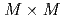 の実対称密行列の固有値分解であり、その計算のため、バッチ形式固有値分解ソルバEigenGを新たに開発した。EigenGによるバッチ形式固有値分解は、既存ライブラリであるcuSolverに対して64倍の高速化を達成した。
の実対称密行列の固有値分解であり、その計算のため、バッチ形式固有値分解ソルバEigenGを新たに開発した。EigenGによるバッチ形式固有値分解は、既存ライブラリであるcuSolverに対して64倍の高速化を達成した。
長谷川 雄太; 小野寺 直幸; 朝比 祐一; 井戸村 泰宏
第35回数値流体力学シンポジウム講演論文集(インターネット), 3 Pages, 2021/12
われわれは、実時間都市風況解析コードCityLBMの開発を行なっており、本稿では、Tesla A100 GPUを用いたCityLBMの性能測定結果を示す。ノード内(NVlink)とノード間(Infiniband)による階層的なネットワークアーキテクチャに対する通信の最適化のため、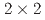 や
や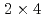 のプロセスをブロック化してノード内複数GPUの計算領域を局所に集中させる、2次元領域分割のブロッキングを導入した。24億格子の大規模計算にて、強スケーリング測定を行った。その結果、80GPUから256GPUまでのスケーリングで2.81倍の高速化、および、領域分割のブロッキングによる1.15倍の高速化といった、良好なスケーリングと計算性能が得られた。これにより、水平方向5.7km四方・1m解像度の風況シミュレーションにおいて、実時間よりも1.32倍速い計算を達成した。
のプロセスをブロック化してノード内複数GPUの計算領域を局所に集中させる、2次元領域分割のブロッキングを導入した。24億格子の大規模計算にて、強スケーリング測定を行った。その結果、80GPUから256GPUまでのスケーリングで2.81倍の高速化、および、領域分割のブロッキングによる1.15倍の高速化といった、良好なスケーリングと計算性能が得られた。これにより、水平方向5.7km四方・1m解像度の風況シミュレーションにおいて、実時間よりも1.32倍速い計算を達成した。
朝比 祐一; Latu, G.*; Bigot, J.*; Grandgirard, V.*
Proceedings of 2021 International Workshop on Performance, Portability, and Productivity in HPC (P3HPC) (Internet), p.79 - 91, 2021/11
本論文では、性能可搬な運動論的プラズマシミュレーションコードのための最適化手法について論じる。まず、性能可搬ライブラリKokkosと指示行(OpenACC/OpenMP)により、単一実装でCPU、GPUで実行可能な運動論的プラズマシミュレーションコードを開発した。これに最適化を施し、Intelや富士通のCPUおよびNvidia GPUにおいて最適化の効果を評価した。その結果、OpenACC/OpenMPでは1.07倍から1.39倍の性能向上が見られ、Kokkos版では、1.00倍から1.33倍の性能向上が見られた。複数の実装による様々なカーネルの最適化手法の効果を多数のデバイスにおいて調査した本成果は、最適化手法として幅広く利用可能と言える。Kokkosは複数のデータ構造やループ構造を単一コードによって表現することに長けており、CPUとGPU両方において高い性能を発揮するために適したフレームワークであると確認した。
朝比 祐一; 畑山 そら*; 下川辺 隆史*; 小野寺 直幸; 長谷川 雄太; 井戸村 泰宏
Proceedings of 2021 IEEE International Conference on Cluster Computing (IEEE Cluster 2021) (Internet), p.686 - 691, 2021/10
被引用回数:3 パーセンタイル:69.51(Computer Science, Hardware & Architecture)多重解像度の定常流を予測する畳み込みニューラルネットワークを開発した。本モデルは、最先端の画像変換モデルpix2pixHDに基づき、パッチ化された符合付き距離関数から高解像度の流れ場の予測が可能である。高解像度データをパッチ化することにより、pix2pixHDと比べてメモリ使用量を削減した。
朝比 祐一; 畑山 そら*; 下川辺 隆史*; 小野寺 直幸; 長谷川 雄太; 井戸村 泰宏
計算工学講演会論文集(CD-ROM), 26, 4 Pages, 2021/05
多重解像度の定常流流れ場を符合付き距離関数から予測するConvolutional Neural networkモデルを開発した。高解像度の画像生成を可能とするネットワークPix2PixHDをパッチ化された高解像度データに適用することで、通常のPix2PixHDよりメモリ使用量を削減しつつ、高解像度流れ場の予測が可能であることを示した。
朝比 祐一; 藤井 恵介*
プラズマ・核融合学会誌, 97(2), p.86 - 92, 2021/02
本研究では、5次元ジャイロ運動論的シミュレーションによる大規模データを、データ駆動科学的手法により解析した。まず、少数の波が支配的なコヒーレントな状態と様々な波が入り乱れる乱雑な状態の判別を、特異値分解を用いて行った。これにより突発的に起こる熱輸送現象のあとプラズマは乱雑な状態になること、乱雑さはその後自発的に減少すること、次の突発現象はそのような自己組織化の後に起きることが明らかになった。この過程はLandau減衰をはじめとする速度空間構造の変化と密接に変化していると考えられる。しかし、従来手法では5次元位相空間構造の時系列解析は不可能であった。そこでさらに主成分分析による位相空間構造データの圧縮技術を開発した。圧縮されたデータを利用しても突発的輸送が表現できることや、どのような位相空間構造が突発的輸送と関連しているかを論じる。
井戸村 泰宏; Obrejan, K.*; 朝比 祐一; 本多 充*
Physics of Plasmas, 28(1), p.012501_1 - 012501_11, 2021/01
被引用回数:9 パーセンタイル:59.06(Physics, Fluids & Plasmas)運動論的電子,バルクイオン,低Zおよび中Zのトレーサ不純物を含む大域的full-fジャイロ運動論シミュレーションを用いてイオン温度勾配駆動(ITG)乱流におけるトレーサ不純物輸送を調べた。この結果、乱流粒子輸送に加えて、乱流輸送と新古典輸送の相乗効果による拡張新古典輸送がトレーサ不純物輸送に大きく寄与することがわかった。ITGモードのバースト的励起が電子とバルクイオンの非両極性乱流粒子束を生成し、これが両極性条件に従う径電場の速い成長をもたらす。これに伴う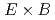 流の発散が磁気ドリフトによる輸送に関連する上下非対称な密度揺動を圧縮する。この密度揺動の振幅は圧縮効果と磁力線方向運動による帰還電流の競合によって決まるため、拡張新古典輸送はイオン質量に依存する。この機構は温度には働かず、粒子輸送のみを選択的に増大する。
流の発散が磁気ドリフトによる輸送に関連する上下非対称な密度揺動を圧縮する。この密度揺動の振幅は圧縮効果と磁力線方向運動による帰還電流の競合によって決まるため、拡張新古典輸送はイオン質量に依存する。この機構は温度には働かず、粒子輸送のみを選択的に増大する。
朝比 祐一; 藤井 恵介*; Heim, D. M.*; 前山 伸也*; Garbet, X.*; Grandgirard, V.*; Sarazin, Y.*; Dif-Pradalier, G.*; 井戸村 泰宏; 矢木 雅敏*
Physics of Plasmas, 28(1), p.012304_1 - 012304_21, 2021/01
被引用回数:6 パーセンタイル:42.02(Physics, Fluids & Plasmas)プラズマ乱流の運動論的シミュレーションによって得られた5次元分布関数の時系列データに主成分分析を適用した。これにより、3桁におよぶデータ圧縮を実現しつつ、83%の累積寄与率を保持できた。各主成分ごとの熱輸送への寄与を調べることで、雪崩的熱輸送には速度空間の共鳴構造が関連していることが明らかとなった。
小野寺 直幸; 井戸村 泰宏; 朝比 祐一; 長谷川 雄太; 下川辺 隆史*; 青木 尊之*
第34回数値流体力学シンポジウム講演論文集(インターネット), 2 Pages, 2020/12
本研究では、二相流体解析コードJUPITERにおいて、圧力ポアソン方程式に対するマルチグリッド前提共役勾配(MG-CG)ソルバーを開発した。プログラムの開発言語として、C++およびCUDAを用いることで、様々なコンピュータプラットフォームに対応した。CG解法の主な計算カーネルは、GPU, CPU、およびARM上において、ルーフライン性能の0.4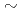 0.75と妥当な性能を達成した。一方で、SpMVカーネルでは、ARM上において、大幅な性能劣化が確認された。その原因を調査したところ、SpMVカーネル内にて関数呼び出しを行うことで、コンパイラの最適化が働かないことが確認された。
0.75と妥当な性能を達成した。一方で、SpMVカーネルでは、ARM上において、大幅な性能劣化が確認された。その原因を調査したところ、SpMVカーネル内にて関数呼び出しを行うことで、コンパイラの最適化が働かないことが確認された。

