


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
井戸村 泰宏; 伊奈 拓也*; Ali, Y.*; 今村 俊幸*
第34回数値流体力学シンポジウム講演論文集(インターネット), 6 Pages, 2020/12
ジャイロ運動論的トロイダル5次元full-fオイラーコードGT5Dにおける半陰解法差分計算用に新しいFP16(半精度)前処理付き省通信クリロフソルバを開発した。このソルバでは、大域的集団通信のボトルネックを省通信クリロフ部分空間法によって解決し、さらに収束特性を向上するFP16前処理によって袖通信を削減した。FP16前処理は演算子の物理特性に基づいて設計し、A64FXで新たにサポートされたFP16SIMD処理を用いた実装した。このソルバをGPUにも移植し、約1,000億格子のITER規模計算の性能を富岳(A64FX)とSummit(V100)で測定した。従来の非省通信型ソルバに比べて、新しいソルバはGT5Dを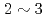 倍加速し、富岳とSummitの両方で5,760CPU/GPUまで良好な強スケーリングが得られた。
倍加速し、富岳とSummitの両方で5,760CPU/GPUまで良好な強スケーリングが得られた。
井戸村 泰宏; 伊奈 拓也*; Ali, Y.*; 今村 俊幸*
Proceedings of International Conference for High Performance Computing, Networking, Storage, and Analysis (SC 2020) (Internet), p.1318 - 1330, 2020/11
被引用回数:2 パーセンタイル:46.34(Computer Science, Information Systems)5次元ジャイロ運動論モデルに基づく次世代核融合実験炉ITERのマルチスケールfull-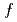 シミュレーションは核融合科学において最も計算コストが大きい問題の一つである。本研究では、新しい混合精度省通信クリロフ法を用いてジャイロ運動論的トロイダル5次元オイラーコードGT5Dを高速化した。演算加速環境における大域的集団通信のボトルネックを省通信クリロフ法によって解決した。これに加えて、A64FXにおいて新たにサポートされたFP16SIMD演算を用いて設計された新しいFP16前処理により、反復(袖通信)の回数と計算コストの両方を削減した。富岳とSummitにおける1,440CPU/GPUを用いた1,000億格子のITER規模シミュレーションに対して、提案手法の処理性能は従来の非省通信クリロフ法に比べてそれぞれ2.8倍, 1.9倍高速化され、5,760CPU/GPUまで良好な強スケーリングを示した。
シミュレーションは核融合科学において最も計算コストが大きい問題の一つである。本研究では、新しい混合精度省通信クリロフ法を用いてジャイロ運動論的トロイダル5次元オイラーコードGT5Dを高速化した。演算加速環境における大域的集団通信のボトルネックを省通信クリロフ法によって解決した。これに加えて、A64FXにおいて新たにサポートされたFP16SIMD演算を用いて設計された新しいFP16前処理により、反復(袖通信)の回数と計算コストの両方を削減した。富岳とSummitにおける1,440CPU/GPUを用いた1,000億格子のITER規模シミュレーションに対して、提案手法の処理性能は従来の非省通信クリロフ法に比べてそれぞれ2.8倍, 1.9倍高速化され、5,760CPU/GPUまで良好な強スケーリングを示した。
井戸村 泰宏; 伊奈 拓也*; Ali, Y.*; 今村 俊幸*
Proceedings of Joint International Conference on Supercomputing in Nuclear Applications + Monte Carlo 2020 (SNA + MC 2020), p.225 - 230, 2020/10
ジャイロ運動論的トロイダル5次元オイラーコードGT5Dにおける半陰解法差分ソルバ向けに新しいFP16(半精度)前処理付き省通信型クリロフソルバを開発した。このソルバでは、大域的集団通信のボトルネックを省通信型クリロフ部分空間法を用いて解決し、FP16前処理を用いて収束特性を改善することで袖通信の回数を削減した。FP16前処理は演算子の物理特性に基づいて設計され、A64FXにおいて新たにサポートされたFP16SIMD演算を用いて実装された。本ソルバは富岳(A64FX)とSummit(V100)に移植され、JAEA-ICEX(Haswell)に比べてそれぞれ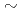 63倍, 29倍のソケットあたり性能の向上を達成した。
63倍, 29倍のソケットあたり性能の向上を達成した。
小野寺 直幸; 井戸村 泰宏; Ali, Y.*; 山下 晋; 下川辺 隆史*; 青木 尊之*
Proceedings of Joint International Conference on Supercomputing in Nuclear Applications + Monte Carlo 2020 (SNA + MC 2020), p.210 - 215, 2020/10
本研究では、ブロック型局所細分化(AMR)法に基づくPoisson解法のGPU高速化を実施した。ブロック型AMR法はGPUに適したデータ構造であり、複雑な構造物で構成された原子炉等の解析に必須な解析手法である。これに、最新の前処理手法であるマルチグリッド(MG)法を共役勾配(CG)法へと組み合わせることで、計算の高速化を実現した。MG-CG法を構成する計算カーネルをGPUスーパーコンピュータであるTSUBAME3.0上にて測定した結果、ベクトル-ベクトル和、行列-ベクトル積、およびドット積の帯域幅は、ピークパフォーマンスの約60%となり、良好なパフォーマンスを実現した。更に、MG法の前処理手法として、3段のVサイクル法および各段に対してRed-Black SOR法を適用した手法を用いて、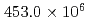 格子点の大規模問題の解析を実施した結果、元の前処理付きCG法と比較して、反復回数を30%未満に削減すると共に、2.5倍の計算の高速化を達成した。
格子点の大規模問題の解析を実施した結果、元の前処理付きCG法と比較して、反復回数を30%未満に削減すると共に、2.5倍の計算の高速化を達成した。
小野寺 直幸; 井戸村 泰宏; Ali, Y.*; 下川辺 隆史*; 青木 尊之*
計算工学講演会論文集(CD-ROM), 25, 4 Pages, 2020/06
原子力機構では3次元多相流体解析手法としてJUPITERを開発している。本研究では、JUPITERの圧力Poisson方程式解法として、適合細分化格子(AMR)を用いたマルチグリッド前提条件付き共役勾配法(P-CG)を開発した。計算の高速化として、全ての計算カーネルはCUDAを用いて実装すると共に、GPUスーパーコンピュータ上にて高い性能を発揮する様に最適化した。開発したマルチグリッド圧力Poisson解法は、オリジナルのP-CG法と比較して約1/7の反復回数で収束することが確認された。また、TSUBAME3.0上で8から216GPUまでの強スケーリング性能測定により、更なる3倍の高速化が達成された。
Ali, Y.*; 小野寺 直幸; 井戸村 泰宏; 伊奈 拓也*; 今村 俊幸*
Proceedings of 10th Workshop on Latest Advances in Scalable Algorithms for Large-Scale Systems (ScalA 2019), p.1 - 8, 2019/11
被引用回数:11 パーセンタイル:93.69(Computer Science, Theory & Methods)大規模線形問題の反復法ソルバはCFDコードで共通に用いられる。前処理付共役勾配(P-CG)法は最も広く用いられている反復法の一つである。しかしながら、P-CG法では、特に演算加速環境において、大域的集団通信が重要なボトルネックとなる。この問題を解決するために、省通信版のP-CG法がますます重要になっている。本論文では多相CFDコードJUPITERにおけるP-CG法と前処理付チェビシェフ基底省通信CG(P-CBCG)法を最新のV100GPUに移植する。全てのGPUカーネルは高度に最適化され約90%のルーフライン性能を達成し、ブロックヤコビ前処理はGPUの高い演算性能を引き出すように再設計し、さらに残された袖通信のボトルネックは通信と計算のオーバーラップによって回避した。P-CG法とP-CBCG法の全体性能は大域的集団通信と袖通信の省通信特性によって左右され、GPUあたりのノード間通信帯域が重要となることが示された。開発したGPUソルバはKNLにおける以前のCPUソルバの2倍に加速され、Summitにおいて7,680GPUまで良好な強スケーリングを達成した。
小野寺 直幸; 井戸村 泰宏; Ali, Y.*; 下川辺 隆史*
Proceedings of 9th Workshop on Latest Advances in Scalable Algorithms for Large-Scale Systems (ScalA 2018) (Internet), p.9 - 16, 2018/11
被引用回数:10 パーセンタイル:92.63(Computer Science, Theory & Methods)計算の高速化に向けて適合細分化格子(AMR)法を適用した格子ボルツマン法(LBM)に対して、通信削減マルチタイムステップ法(CRMT)を提案した。本手法はテンポラルブロッキング法に基づく定式化を行うことで、GPU計算で大きなボトルネックとなる通信回数の削減が可能となる。東京工業大学のTSUBAMEおよび東京大学のReedbushスーパーコンピュータにて性能測定を実施した結果、通信コストが64%に削減され、200GPUまでの弱および強スケーリング結果が改善された。以上の高速化により、2km四方の計算領域に対して1m解像度の風速5msの実時間解析が可能であることが示された。
Widmann, M.*; Lee, S.-Y.*; Rendler, T.*; Son, N. T.*; Fedder, H.*; Paik, S.*; Yang, L.-P.*; Zhao, N.*; Yang, S.*; Booker, I.*; et al.
Nature Materials, 14(2), p.164 - 168, 2015/02
被引用回数:508 パーセンタイル:99.58(Chemistry, Physical)Single silicon vacancy (V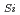 ) in silicon carbide (SiC) was studied from the point of view of single photon source for quantum computing. The V centers were created in high purity semi-insulating hexagonal (4H)-SiC by 2 MeV electron irradiation with fluences up to 5
) in silicon carbide (SiC) was studied from the point of view of single photon source for quantum computing. The V centers were created in high purity semi-insulating hexagonal (4H)-SiC by 2 MeV electron irradiation with fluences up to 5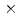 10
10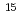 /cm
/cm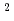 . No subsequent annealing was carried out. A couple of solid immersion lens (SIL) with 20
. No subsequent annealing was carried out. A couple of solid immersion lens (SIL) with 20 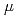 m diameter were created on samples by ion milling using 40 keV Ga focused ion beam. A typical home-built confocal setup was used after optimizing for emission in the wavelength range around 900 nm. As a result, optically detected electron spin resonance (ODMR) for V was observed at room temperature (RT). Using ODMR, Rabi oscillations were also observed, and the Rabi frequency increased with increasing applied-magnetic field. In addition, spin relaxation time T
m diameter were created on samples by ion milling using 40 keV Ga focused ion beam. A typical home-built confocal setup was used after optimizing for emission in the wavelength range around 900 nm. As a result, optically detected electron spin resonance (ODMR) for V was observed at room temperature (RT). Using ODMR, Rabi oscillations were also observed, and the Rabi frequency increased with increasing applied-magnetic field. In addition, spin relaxation time T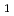 and T
and T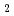 were detected to be 500 s and 160 s, respectively.
were detected to be 500 s and 160 s, respectively.
Waldherr, G.*; Wang, Y.*; Zaiser, S.*; Jamali, M.*; Schulte-Herbr ggen, T.*; 阿部 浩之; 大島 武; 磯谷 順一*; Du, J. F.*; Neumann, P.*; et al.
ggen, T.*; 阿部 浩之; 大島 武; 磯谷 順一*; Du, J. F.*; Neumann, P.*; et al.
Nature, 506(7487), p.204 - 207, 2014/02
被引用回数:471 パーセンタイル:99.58(Multidisciplinary Sciences)量子ビットが担う"重ね合わせ"という量子情報は、外部との意図しない相互作用により容易に壊されるので、量子エラー訂正無しでは量子コンピューティングは実現困難である。ダイヤモンド中のカラーセンターの一つであるNVセンターの単一分子に相当する単一欠陥を用いて、電子スピン1個と核スピン3個からなるハイブリッド量子レジスタを作製(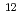 C 99.8%濃縮した合成ダイヤモンド結晶に電子線照射と熱処理によりNVセンターを形成)し、室温動作の固体スピン量子キュービットでは世界で初めて量子エラー訂正のプロトコルの実行に成功した。この方法はスケーラブルなので、フォールト・トレラントな量子操作を多量子ビットへ拡張することが可能となり、固体量子情報デバイス実現への道を開くものである。
C 99.8%濃縮した合成ダイヤモンド結晶に電子線照射と熱処理によりNVセンターを形成)し、室温動作の固体スピン量子キュービットでは世界で初めて量子エラー訂正のプロトコルの実行に成功した。この方法はスケーラブルなので、フォールト・トレラントな量子操作を多量子ビットへ拡張することが可能となり、固体量子情報デバイス実現への道を開くものである。
Bonfigli, F.*; Faenov, A. Y.; Flora, F.*; Francucci, M.*; Gaudio, P.*; Lai, A.*; Martellucci, S.*; Montereali, R. M.*; Pikuz, T.*; Reale, L.*; et al.
Microscopy Research and Technique, 71(1), p.35 - 41, 2008/01
被引用回数:30 パーセンタイル:76.53(Anatomy & Morphology)High contrast imaging of in vivo cells with submicron spatial resolution was obtained with a contact water window X-ray microscopy technique using a point-like, laser-plasma produced water-window X-ray radiation source and LiF crystals as detectors. The powerful performance of LiF crystals allowed to detect the exudates of Chlorella cells in their living medium and their spatial distribution in situ, without any special sample preparation
Batistoni, P.*; Angelone, M.*; Bettinali, L.*; Carconi, P.*; Fischer, U.*; Kodeli, I.*; Leichtle, D.*; 落合 謙太郎; Perel, R.*; Pillon, M.*; et al.
Fusion Engineering and Design, 82(15-24), p.2095 - 2104, 2007/10
被引用回数:27 パーセンタイル:83.96(Nuclear Science & Technology)ヨーロッパ核融合技術プログラムにおいて、EUが提案している核融合テストブランケットモジュール模擬体系の核融合中性子工学実験をイタリアENEAの核融合中性子源FNGで実施した。ヘリウム冷却型ぺブルベッドタイプを模擬した体系内に生成するトリチウム量を炭酸リチウムペレットによる液体シンチレーションカウンター法でイタリア,ドイツ及び日本と共同して測定した。またモンテカルロ計算によるトリチウム生成量の評価も同時に実施し、計算値が誤差9%程度で一致することを確認した。
 produced by low-energy ion implantation
produced by low-energy ion implantationAli, M.; 馬場 祐治; 関口 哲弘; Li, Y.; 山本 博之
Photon Factory Activity Report 1998, P. 36, 1999/11
シリコン単結晶に低エネルギー窒素イオンを注入し、表面に生成したSiN(0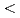 x4/3)層の電子構造をX線光電子分光法(XPS)及びX線吸収端微細構造法(XANES)により測定した。Si 1sのXPSスペクトルによると、窒素注入量が10
x4/3)層の電子構造をX線光電子分光法(XPS)及びX線吸収端微細構造法(XANES)により測定した。Si 1sのXPSスペクトルによると、窒素注入量が10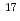 atoms/cmのオーダーでは、中間組成をもつSi
atoms/cmのオーダーでは、中間組成をもつSi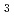 N(x=1,2,3)がいったん生成するが、10
N(x=1,2,3)がいったん生成するが、10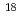 atoms/cm以上では、化学量論組成をもつSiN
atoms/cm以上では、化学量論組成をもつSiN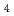 層に移行する。しかし、XPSより深い領域の電子構造を反映する電子収量法によるSi K-吸収端のXANESスペクトルでは、この物質層にも依然として非化学量論組成をもつSiN(x=1,2,3)が含まれていることがわかった。注入後の試料を800Kまでアニールすることにより、これらの中間層は消え、完全にSiN層に変化することが明らかとなった。
層に移行する。しかし、XPSより深い領域の電子構造を反映する電子収量法によるSi K-吸収端のXANESスペクトルでは、この物質層にも依然として非化学量論組成をもつSiN(x=1,2,3)が含まれていることがわかった。注入後の試料を800Kまでアニールすることにより、これらの中間層は消え、完全にSiN層に変化することが明らかとなった。
S) on Si(100) following excitation of adsorbate or substrate core level関口 哲弘; 馬場 祐治; Li, Y.; Ali, M.
Photon Factory Activity Report 1998, Part B, P. 67, 1999/11
放射光のX線エネルギーを変化させることにより特定の元素の内殻電子準位を選択的に励起することができる。これは、例えば、ディジタル・エッチング(薄膜吸着 光照射(反応)薄膜吸着…を単分子レベルで進行させようというアイデア)に応用できる可能性がある。本研究では表面励起とバルク励起の選択性を見積もるため、シリコン(Si)基板上にイオウ(s)化合物((CHS))を吸着させた系に対し、基板(Si 1s)励起と吸着種(S 1s)の内殻励起により引き出される解離反応を調べた。放射光照射により生じるイオン脱離生成物を四重極質量分析により検出した。結果としてはイオウ原子イオンがあるイオウ内殻共鳴励起で生じ、基板Si励起では検出限界以下という大きな選択性が観測された。励起される吸着分子の数は歴される基板原子数に比べ数桁も小さいにもかかわらず、生成収量は大きいという非常に高い選択性が示された。
光照射(反応)薄膜吸着…を単分子レベルで進行させようというアイデア)に応用できる可能性がある。本研究では表面励起とバルク励起の選択性を見積もるため、シリコン(Si)基板上にイオウ(s)化合物((CHS))を吸着させた系に対し、基板(Si 1s)励起と吸着種(S 1s)の内殻励起により引き出される解離反応を調べた。放射光照射により生じるイオン脱離生成物を四重極質量分析により検出した。結果としてはイオウ原子イオンがあるイオウ内殻共鳴励起で生じ、基板Si励起では検出限界以下という大きな選択性が観測された。励起される吸着分子の数は歴される基板原子数に比べ数桁も小さいにもかかわらず、生成収量は大きいという非常に高い選択性が示された。
小野寺 直幸; 井戸村 泰宏; Ali, Y.*
no journal, ,
放射性物質のリアルタイムシミュレーションは核セキュリティの観点から非常に重要である。都市は多くの建物や路地を含むため、その詳細な気流を解析するためには大規模なCFDの実施が必要となる。ブロックベースのAMR法に基づく格子ボルツマン法を用いることで、マルチスケールの気流解析が実現できる。計算コードはリアルタイムシミュレーションを実施するために、GPUを用いて開発を行なっている。本研究では並列計算性能の向上のために、テンポラルブロッキング法を用いた省通信型マルチタイムステップアルゴリズムを提案した。日本原子力研究開発機構のGPUクラスタ(NVIDIA P100)に対して性能測定を行なった結果、488MLUPSの非常に高い計算性能の達成および、通信量の削減が確認された。
今村 俊幸*; 井戸村 泰宏; 伊奈 拓也*; 山下 晋; 小野寺 直幸; Ali, Y.*; 山田 進
no journal, ,
ポスト京におけるエクサスケール計算に向けて、省通信アルゴリズムに基づく新たな行列ソルバが開発されている。本講演では、3次元多相熱流動解析CFDコードJUPITERで用いられている2つの手法を紹介する。一つは省通信クリロフ部分空間法である。この手法では複数の基底ベクトルの生成、直交化を一度に処理することで大域的集団通信の回数を削減する。もう一つ手法であるマルチグリッド前処理付クリロフ部分空間法は収束特性を飛躍的に向上し、反復、すなわち、大域的集団通信の回数を削減する。最新のメニーコア環境におけるこれらの手法の比較を議論する。
井戸村 泰宏; Ali, Y.*; 小野寺 直幸; 長谷川 雄太; 伊奈 拓也*
no journal, ,
大規模CFDシミュレーションにおいてクリロフソルバが全計算コストの約90%を占める。そのようなCFDコードを加速するために、前処理付共役勾配(PCG)法, 前処理付チェビシェフ基底省通信共役勾配(P-CBCG)法, 省通信一般化最小残差(CA-GMRES)法をGPU環境に移植した。本講演ではこれらのソルバをOpenACC, CUDA、および、CUDA aware MPIを用いて移植する上でのノウハウを議論する。
Ali, Y.*; 小野寺 直幸; 井戸村 泰宏; 伊奈 拓也*; 今村 俊幸*
no journal, ,
大規模原子力CFDシミュレーションにおいてクリロフソルバは全体計算コストの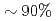 を占める。このようなCFDコードを加速するために、従来の前処理付共役残差(P-CG)法、および、前処理付チェビシェフ基底省通信共役残差(P-CBCG)法、省通信一般化最小残差(CA-GMRES)法という2種類の最新省通信アルゴリズムをGPUに移植した。本講演ではOpenACCとCUDAを用いた実装に対する性能移植性と性能向上のトレードオフを議論するとともに、最新のGPUスーパーコンピュータにおける性能テストを示す。
を占める。このようなCFDコードを加速するために、従来の前処理付共役残差(P-CG)法、および、前処理付チェビシェフ基底省通信共役残差(P-CBCG)法、省通信一般化最小残差(CA-GMRES)法という2種類の最新省通信アルゴリズムをGPUに移植した。本講演ではOpenACCとCUDAを用いた実装に対する性能移植性と性能向上のトレードオフを議論するとともに、最新のGPUスーパーコンピュータにおける性能テストを示す。
小野寺 直幸; 井戸村 泰宏; Ali, Y.*; 山下 晋; 伊奈 拓也*; 今村 俊幸*
no journal, ,
原子炉の非定常熱流解析は、効率的な設計と安全性の観点から非常に重要である。原子力機構では、それらの解析を実施するためにJUPITERコードのPoisson方程式に対してP-CGおよびP-CBCG法のGPU実装により計算を高速化を行なっている。Poisson方程式の計算カーネルはCUDAを用いて記述し、更に最新のVoltaアーキテクチャのGPUで高い性能を実現するように最適化を行った。開発したソルバーにより、Summit(NVIDIA TESLA V100), ABCI(NVIDIA TESLA V100), Oakforest-PACS(Intel Knights Landing)で2,048GPU/CPUまで優れたスケーリングが得られると共に、Oakforest-PACSに対して、Summitで1.21.6倍、ABCIで1.41.7倍の性能向上が示された。
Ali, Y.*; 伊奈 拓也*; 小野寺 直幸; 井戸村 泰宏
no journal, ,
圧力ポアソン方程式のクリロフ部分空間法ソルバは大規模多相CFDシミュレーションにおいて全計算コストのを占める。このポアソンソルバを加速するためにブロックヤコビ(BJ)前処理付きチェビシェフ基底共役勾配法(CBCG)ソルバをP100GPUに移植した。CBCGソルバはBJ前処理, 疎行列ベクトル積(SpMV), 非正方行列積から構成される。本研究ではスレッド・ブロック並列処理と効率的なコアレスドロードのためにBJ前処理を再設計し、非正方行列積にBatched GEMMを適用した。上記最適化により全ての主要カーネルでルーフラインに基づく理論性能のを達成し、CPUノードに比べて一桁以上のノード性能向上が得られた。
小野寺 直幸; 井戸村 泰宏; Ali, Y.*; 下川辺 隆史*
no journal, ,
福島第一原子力発電所の廃炉においては熱流動解析が重要なテーマの一つである。日本原子力研究開発機構(JAEA)では、非圧縮性Navier-Stokes方程式の解法であるJUPITERコードを用いて、デブリの空冷解析評価を行なっている。しかしながら、実機を対象とした解析の実施のためには、非常に多くの計算コストが必要となる。本研究では、GPUを用いた大規模計算に適した格子ボルツマン法に基づく熱流動解析手法であるCityLBMコードを構築している。本発表では、CityLBMコードによる自然対流実験との比較を示す。
