


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
朝比 祐一; 小野寺 直幸; 長谷川 雄太; 下川辺 隆史*; 芝 隼人*; 井戸村 泰宏
Boundary-Layer Meteorology, 186(3), p.659 - 692, 2023/03
被引用回数:2 パーセンタイル:25.47(Meteorology & Atmospheric Sciences)定点観測された風向などの時系列データおよび汚染物質放出点を入力として、汚染物質の地表面拡散分布を予測する機械学習モデルを開発した。問題設定としては、一様風が都市部へ流入し、都市部内にランダムに設置された汚染物質放出点から汚染物質が拡散するという状況を扱っている。機械学習モデルとしては、汚染物質放出点から汚染物質の拡散分布を予測するCNNモデルを用いた。風向などの時系列データは、Transformerや多層パーセプトロンによってEncodeし、CNNへと引き渡す。これによって、現実的に取得可能な定点測時系列データのみを入力とし、実用上価値の高い汚染物質の地表面拡散分布の予測を可能とした。同一のモデルを用いて定点観測時系列データから汚染物質放出点の予測が可能であることも示した。
朝比 祐一; 小野寺 直幸; 長谷川 雄太; 下川辺 隆史*; 芝 隼人*; 井戸村 泰宏
計算工学講演会論文集(CD-ROM), 27, 5 Pages, 2022/06
都市風況解析コードCityLBMをAMD社のMI100 GPUへと移植し、CityLBMの性能をNVIDIA P100, V100, A100およびAMD MI100において測定した。ホスト間でのMPI通信を利用した場合、CityLBMの性能はMI100においてV100と比べ20%程度向上した。適合細分化格子法に起因する補間カーネルを除く演算カーネルでは、MI100においてV100と比べ性能向上を確認した。
小野寺 直幸; 井戸村 泰宏; 長谷川 雄太; 下川辺 隆史*; 青木 尊之*
計算工学講演会論文集(CD-ROM), 27, 4 Pages, 2022/06
高度計算機技術開発室では、風況デジタルツインの実現に向けて、風況解析コードCityLBMを開発している。CityLBMは、計算領域周辺の境界条件をメソスケール気象データに同化させるナッジング法を導入することで、現実の風況を反映した解析が可能である。しかしながら、従来のナッジング法では、ナッジング係数が一定のため、大気状態が変化するような長時間解析の乱流強度を再現できない問題点が挙げられる。そこで、本研究では、パーティクルフィルタを用いた動的なナッジング・パラメータの最適化手法を提案する。CityLBMの検証として、米国オクラホマシティの風況実験に対する解析を実施した。シミュレーションと観測のそれぞれで得られる乱流強度の誤差を低減するようにナッジング係数を更新した結果、シミュレーションにおいて終日の大気境界層を再現できることを確認した。
朝比 祐一; 畑山 そら*; 下川辺 隆史*; 小野寺 直幸; 長谷川 雄太; 井戸村 泰宏
Proceedings of 2021 IEEE International Conference on Cluster Computing (IEEE Cluster 2021) (Internet), p.686 - 691, 2021/10
被引用回数:3 パーセンタイル:69.51(Computer Science, Hardware & Architecture)多重解像度の定常流を予測する畳み込みニューラルネットワークを開発した。本モデルは、最先端の画像変換モデルpix2pixHDに基づき、パッチ化された符合付き距離関数から高解像度の流れ場の予測が可能である。高解像度データをパッチ化することにより、pix2pixHDと比べてメモリ使用量を削減した。
小野寺 直幸; 井戸村 泰宏; 長谷川 雄太; 中山 浩成; 下川辺 隆史*; 青木 尊之*
Boundary-Layer Meteorology, 179(2), p.187 - 208, 2021/05
被引用回数:18 パーセンタイル:70.48(Meteorology & Atmospheric Sciences)汚染物質の拡散解析手法CityLBMは、GPUスーパーコンピュータ上において、適合細分化格子(AMR)法を適用する事で、数kmの解析領域の実時間解析が可能である。本論文では、CityLBMの検証としてオクラホマ市で実施された野外拡散実験(JU2003)に対する解析を実施した。計算条件として、Weather Research and Forecasting(WRF)モデルを用いた風況条件および、建物と植生を考慮した地表面データをCityLBMに与えることで、JU2003の実験条件を再現した。さらにアンサンブル計算の実施により、乱流の不確実性を軽減した。汚染物質の時間平均濃度および最大値を実験測定値と比較した結果、アンサンブル計算により解析精度を向上すると共に、2m解像度・4km四方の解析では、24個の計測値に対して70%の高い割合でFactor2を満たす事を確認した。
朝比 祐一; 畑山 そら*; 下川辺 隆史*; 小野寺 直幸; 長谷川 雄太; 井戸村 泰宏
計算工学講演会論文集(CD-ROM), 26, 4 Pages, 2021/05
多重解像度の定常流流れ場を符合付き距離関数から予測するConvolutional Neural networkモデルを開発した。高解像度の画像生成を可能とするネットワークPix2PixHDをパッチ化された高解像度データに適用することで、通常のPix2PixHDよりメモリ使用量を削減しつつ、高解像度流れ場の予測が可能であることを示した。
小野寺 直幸; 井戸村 泰宏; 長谷川 雄太; 下川辺 隆史*; 青木 尊之*
計算工学講演会論文集(CD-ROM), 26, 3 Pages, 2021/05
本研究では、二相流体解析コードJUPITER-AMRに対して、圧力ポアソン方程式に対する混合精度前処理手法を開発した。マルチグリッド前処理手法として、3段のVサイクルの幾何学的MG法およびキャッシュを再利用したSOR(CR-SOR)法を適用した。原子力工学問題での性能測定として、バンドル体系に対する多相流体解析を実施した。計算速度として、単精度演算を適用する事で、倍精度演算の75%へと削減すると共に、強スケーリング性能においては、32台から96台のGPUを利用する事で1.88倍を実現した。
小野寺 直幸; 井戸村 泰宏; 長谷川 雄太; 山下 晋; 下川辺 隆史*; 青木 尊之*
Proceedings of International Conference on High Performance Computing in Asia-Pacific Region (HPC Asia 2021) (Internet), p.120 - 128, 2021/01
被引用回数:0 パーセンタイル:0.00(Computer Science, Hardware & Architecture)本研究では、二相流体解析コードJUPITERに対して、マルチグリッド前処理付き共役勾配(MG-CG)法を開発した。MG法は、3段のVサイクルMG法に基づいて構築し、各段に対して、RB-SOR法およびGPUのキャッシュを再利用したCR-SORを開発・適用した。性能測定として、バンドル体系に対する気液二相流体解析を行った。RB-SOR法およびCR-SOR法を適用したMG-CG法では、MG法を適用しないPCG法と比較して、収束までの反復回数を15%と9%以下に削減するとともに、3.1倍, 5.9倍の計算速度が達成された。以上の結果から、本研究で開発したMG-CG法は、GPUを用いたスーパーコンピュータ上にて、効率的に大規模な二相流体解析が可能であることが示された。
小野寺 直幸; 井戸村 泰宏; 朝比 祐一; 長谷川 雄太; 下川辺 隆史*; 青木 尊之*
第34回数値流体力学シンポジウム講演論文集(インターネット), 2 Pages, 2020/12
本研究では、二相流体解析コードJUPITERにおいて、圧力ポアソン方程式に対するマルチグリッド前提共役勾配(MG-CG)ソルバーを開発した。プログラムの開発言語として、C++およびCUDAを用いることで、様々なコンピュータプラットフォームに対応した。CG解法の主な計算カーネルは、GPU, CPU、およびARM上において、ルーフライン性能の0.4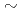 0.75と妥当な性能を達成した。一方で、SpMVカーネルでは、ARM上において、大幅な性能劣化が確認された。その原因を調査したところ、SpMVカーネル内にて関数呼び出しを行うことで、コンパイラの最適化が働かないことが確認された。
0.75と妥当な性能を達成した。一方で、SpMVカーネルでは、ARM上において、大幅な性能劣化が確認された。その原因を調査したところ、SpMVカーネル内にて関数呼び出しを行うことで、コンパイラの最適化が働かないことが確認された。
小野寺 直幸; 井戸村 泰宏; Ali, Y.*; 山下 晋; 下川辺 隆史*; 青木 尊之*
Proceedings of Joint International Conference on Supercomputing in Nuclear Applications + Monte Carlo 2020 (SNA + MC 2020), p.210 - 215, 2020/10
本研究では、ブロック型局所細分化(AMR)法に基づくPoisson解法のGPU高速化を実施した。ブロック型AMR法はGPUに適したデータ構造であり、複雑な構造物で構成された原子炉等の解析に必須な解析手法である。これに、最新の前処理手法であるマルチグリッド(MG)法を共役勾配(CG)法へと組み合わせることで、計算の高速化を実現した。MG-CG法を構成する計算カーネルをGPUスーパーコンピュータであるTSUBAME3.0上にて測定した結果、ベクトル-ベクトル和、行列-ベクトル積、およびドット積の帯域幅は、ピークパフォーマンスの約60%となり、良好なパフォーマンスを実現した。更に、MG法の前処理手法として、3段のVサイクル法および各段に対してRed-Black SOR法を適用した手法を用いて、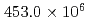 格子点の大規模問題の解析を実施した結果、元の前処理付きCG法と比較して、反復回数を30%未満に削減すると共に、2.5倍の計算の高速化を達成した。
格子点の大規模問題の解析を実施した結果、元の前処理付きCG法と比較して、反復回数を30%未満に削減すると共に、2.5倍の計算の高速化を達成した。
小野寺 直幸; 井戸村 泰宏; Ali, Y.*; 下川辺 隆史*; 青木 尊之*
計算工学講演会論文集(CD-ROM), 25, 4 Pages, 2020/06
原子力機構では3次元多相流体解析手法としてJUPITERを開発している。本研究では、JUPITERの圧力Poisson方程式解法として、適合細分化格子(AMR)を用いたマルチグリッド前提条件付き共役勾配法(P-CG)を開発した。計算の高速化として、全ての計算カーネルはCUDAを用いて実装すると共に、GPUスーパーコンピュータ上にて高い性能を発揮する様に最適化した。開発したマルチグリッド圧力Poisson解法は、オリジナルのP-CG法と比較して約1/7の反復回数で収束することが確認された。また、TSUBAME3.0上で8から216GPUまでの強スケーリング性能測定により、更なる3倍の高速化が達成された。
小野寺 直幸; 井戸村 泰宏; Ali, Y.*; 下川辺 隆史*
Proceedings of 9th Workshop on Latest Advances in Scalable Algorithms for Large-Scale Systems (ScalA 2018) (Internet), p.9 - 16, 2018/11
被引用回数:10 パーセンタイル:92.63(Computer Science, Theory & Methods)計算の高速化に向けて適合細分化格子(AMR)法を適用した格子ボルツマン法(LBM)に対して、通信削減マルチタイムステップ法(CRMT)を提案した。本手法はテンポラルブロッキング法に基づく定式化を行うことで、GPU計算で大きなボトルネックとなる通信回数の削減が可能となる。東京工業大学のTSUBAMEおよび東京大学のReedbushスーパーコンピュータにて性能測定を実施した結果、通信コストが64%に削減され、200GPUまでの弱および強スケーリング結果が改善された。以上の高速化により、2km四方の計算領域に対して1m解像度の風速5msの実時間解析が可能であることが示された。
下川辺 隆史*; 遠藤 敏夫*; 小野寺 直幸; 青木 尊之*
Proceedings of 2017 IEEE International Conference on Cluster Computing (IEEE Cluster 2017) (Internet), p.525 - 529, 2017/09
ステンシルに基づくCFDコードは、規則的なメモリアクセスを持つため、GPUで高い性能を得ることができる。しかしながら、GPUはCPUと比較して、メモリ容量が小さいため、CPUと同様の大きさの問題を解くことができない。そこで、本研究では、CPUのホストメモリとCPUのデバイスメモリの局所性を向上させることが可能な、テンポラルブロッキング法を用いることで、GPUのメモリ容量を超える大きさの計算を可能とした。本研究で開発したフレームワークでは、複雑なコーディングは必要とせずに、テンポラルブロッキング法を含む並列計算用のコードを生成できる。フレームワークを用いて開発した気流解析コードでは、TSUBAME2.5において、GPUのメモリ容量の2倍の計算規模においても、通常のメモリ容量の計算の80%程度の実効性能を達成した。
小野寺 直幸; 井戸村 泰宏; 長谷川 雄太; 中山 浩成; 下川辺 隆史*; 青木 尊之*
no journal, ,
本論文では、風況デジタルツインの実現に向けた現実的な乱流境界層再現のためのデータ同化手法を提案する。本研究グループでは、格子ボルツマン法に基づく汚染物質拡散解析コードCityLBMを開発している。CityLBMは、GPUスーパーコンピュータ上において、適合細分化格子法を用いることで、数km四方の実時間アンサンブル解析が可能である。ここでは、CityLBMの境界条件として、メソスケール気象予測モデルの風況データをナッジング法を用いて同化している。本研究では、観測データに基づいてパーティクルフィルタによりナッジング係数を動的に最適化する手法を新たに提案した。この手法により、終日の風況プロファイルが観測データと一致することが確認され、大気の状態が大きく変化する終日のシミュレーションに適用することが可能となった。
朝比 祐一; 前山 伸也*; Bigot, J.*; Garbet, X.*; Grandgirard, V.*; 藤井 恵介*; 下川辺 隆史*; 渡邉 智彦*; 井戸村 泰宏; 小野寺 直幸; et al.
no journal, ,
大規模流体シミュレーションのためのin-situデータ解析手法およびdeep learningによる流体シミュレーション結果の代理モデルを開発した。新たに開発したin-situデータ処理手法では、MPIアプリとpythonのポスト処理スクリプトが弱結合される。この手法によってファイルを経由しないポスト処理が可能となり、最大2.7倍の性能向上が見られた。また、多重解像度の流れ場予測を可能にするdeep learning代理モデルを開発した。本モデルでは、十分な予測精度と数値シミュレーションに対する大幅な速度向上を実現した。
小野寺 直幸; 長谷川 雄太; 井戸村 泰宏; 朝比 祐一; 河村 拓馬; 伊奈 拓也; 下村 和也; 稲垣 厚至*; 鈴木 真一*; 平野 洪賓*; et al.
no journal, ,
デジタルツインに基づく風況予測は、都市街区内の歩行者に対する熱中症評価や微小粒子状物質の拡散予測などスマートシティ設計・運用に応用など、新たな社会基盤構築に貢献できる技術である。本ポスター発表では、都市街区内の風況デジタルツインの実現に向けた、観測とメソスケール気象データとのデータ同化に基づく風況シミュレーションについて紹介する。
小野寺 直幸; 青木 尊之*; 井戸村 泰宏; 山下 晋; 河村 拓馬; 朝比 祐一; 伊奈 拓也; 長谷川 雄太; 杉原 健太; 下川辺 隆史*; et al.
no journal, ,
エクサスケールスパコンを活用した原子力数値流体力学(CFD)解析の実現に向けて、圧力Poisson解法の混合精度演算の適用による高速化、および、GPU・CPU・ARMプロセッサ等の様々な演算機向けの最適化を実施した。原子力CFD問題であるバンドル体系に対する気液二相流体解析を実施した結果、前処理手法に単精度演算(fp32)を適用することで、倍精度と比較して75%の計算時間で解析が可能であることが確認された。マルチプラットフォーム向けの実装では、マクロを用いて並列ループを置き換えることで、ブロック構造AMR格子版のPoisson解法において、CPU・GPU上での高い演算性能と性能移植性を実現した。一方で、A64FXでの富士通コンパイラによる最適化では、GNU/Intel/NVIDIAのコンパイラと同様の最適化が行われない問題点が明らかとなった。左記の問題に対して、直交格子版JUPITERにおいて、手動での関数インライン化等の最適化を実施することで、高い演算性能を実現した。
杉原 健太; 青木 尊之*; 小野寺 直幸; 井戸村 泰宏; 河村 拓馬; 下川辺 隆史*; 伊奈 拓也; 山下 晋
no journal, ,
原子力機構では多相流解析コードJUPITERを開発し、CPUスパコンを用いた1mm格子解像度のバンドル体系の解析や、更にGPUスパコンを用いた高速化により0.6mm格子解像度の解析を実現した。しかし、以上の解析においても実験結果のボイド率を再現できておらず、更なる高解像度化と気液界面モデルの高精度化が必要となっている。上記課題に対して、今年度のJHPCN課題では、従来の界面の対流項からなる気液界面モデル(THINC/WLIC法)と比較して、界面方向への逆拡散によって数値拡散を抑えることが可能なフェーズ・フィールド法、およびその発展系であるマルチ・フェーズ・フィールド法を適用することで、気液界面捕獲手法を高精度化する。以上の開発により、原子力分野の熱流動解析や産業応用分野の冷却システム等、多数の気泡を含む工学問題における多相流体解析の高精度化が期待できる。以上の内容をポスター発表にて紹介する。
朝比 祐一; 前山 伸也*; Bigot, J.*; Garbet, X.*; Grandgirard, V.*; Obrejan, K.*; Padioleau, T.*; 藤井 恵介*; 下川辺 隆史*; 渡邉 智彦*; et al.
no journal, ,
エクサスケール数値計算のための性能可搬性向上に関する研究を紹介する。特にAMD GPUにおけるプラズマコードの性能や、C++標準言語におけるGPUコードの性能評価結果を示す。またdeep learningを用いた流体計算の代理モデルについても紹介する。
朝比 祐一; 前山 伸也*; Bigot, J.*; Garbet, X.*; Grandgirard, V.*; Obrejan, K.*; Padioleau, T.*; 藤井 恵介*; 下川辺 隆史*; 渡邉 智彦*; et al.
no journal, ,
エクサスケール数値計算のための性能可搬性向上に関する研究を紹介する。特にAMD GPUにおけるプラズマコードの性能や、C++標準言語におけるGPUコードの性能評価結果を示す。またdeep learningを用いた流体計算の代理モデルについても紹介する。
